
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Computer Vision
- Data Augmentation
- matrix multiplication
- Github Copilot
- 동형암호
- NLP
- Model Compression
- Language Modeling
- Knowledge Distillation
- 표현론
- math
- bert
- 자연어처리
- Residual Connection
- 머신러닝
- Copilot
- Knowledge Tracing
- Pre-training
- GPT
- ICML
- KT
- Private ML
- Deep learning
- 딥러닝
- Transformer
- AI
- Natural Language Processing
- Machine Learning
- attention
- Homomorphic Encryption
- Today
- Total
Anti Math Math Club
Privacy Preserving Machine Learning (1) - Federated Learning 본문
Privacy Preserving Machine Learning (1) - Federated Learning
seewoo5 2021. 5. 31. 21:10머신러닝과 딥러닝이 각광을 받으면서 그에 대한 수요 역시 급증하게 되었는데요, (방대한) 데이터에 기반을 두고 있는 ML/DL 기술들을 이용함에 있어서 데이터의 보안에 대해서 한번쯤은 생각해 볼 필요가 있습니다. ImageNet과 같은 공개된 벤치마크 데이터셋의 경우 모든 연구자들이 자유롭게 연구에 사용할 수 있는 반면에, 의료 인공지능에서 사용되는 환자들의 데이터나 GPT-3와 같은 거대한 언어 모델을 사전학습 시키는데에 사용된 말뭉치(text corpus)의 경우 개인정보와 관련된 민감한 데이터가 포함되어있기 때문에 쉽게 구할수도, 구했다고 해도 쉽게 사용할 수도 없습니다. 작년에 발표된 Extract Training Data from Large Language Models라는 논문에서는 사전학습된 GPT-2로부터 역으로 주소나 전화번호같은 개인정보가 포함된 훈련 데이터를 추출하는것이 가능함을 보이기도 했죠. 그렇기 때문에 인공지능 모델을 만들 때 이러한 보안 이슈를 절대로 무시할 수는 없습니다.
이러한 문제점들을 해결하기 위한 방법으로는 크게 다음과 같은 3가지가 있습니다.
- Federated Learning (연합 학습)
- Differential Privacy (차분 프라이버시)
- Homomorphic Encryption (동형암호)
이번 포스팅에서는 그 중 첫번째인 Federated Learning의 개념에 대해서 설명하고, 몇가지 예시들을 소개하려고 합니다.
예를 들어서, 구글의 서버에 사람의 얼굴 사진을 분류하는 모델이 있고, 이 모델을 핸드폰으로 받아와서 핸드폰 내에 있는 사진들을 분류하는 어플을 만들었다고 생각합시다. 그러면 이제 어플을 사용하는 사람들이 가지고 있는 사진들을 이용해서 기존 모델을 업데이트 하고자 할 때 데이터 보안에 관한 문제가 발생합니다. 새로운 데이터에 해당하는 사진들은 결국 클라이언트들의 사진일텐데, 이를 서버로 가져와서 모델을 훈련시키게 되면 결국 서버는 민감한 데이터를 알 수 있게 되고, 많은 사람들은 이를 원하지 않을 것입니다. 최근에는 페이스북이 유저들의 개인정보를 유출하는 사태도 일어났었죠. 그렇다면, 데이터를 서버로 보내지 않고 모델을 업데이트 하는 방안을 생각해봐야 하는데, 어떻게 해야 할까요?
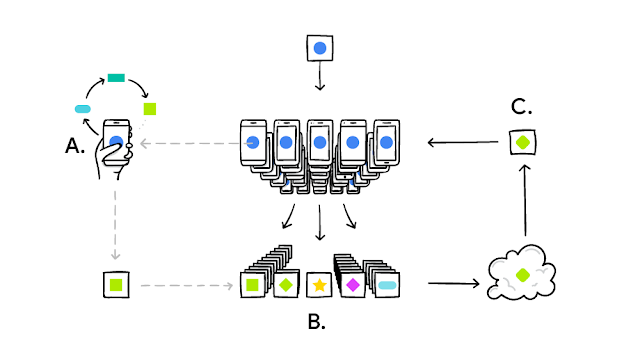
Federated Learning이란, 구글에서 발표한 이 논문에서 처음 제시한 개념으로, 연합 학습이라는 이름처럼 모델을 서로 다른 장치(클라이언트에 해당)에서 학습을 시킨 뒤, 그 결과를 서버로 한데 모아서 원래의 모델을 업데이트 하는 것을 말합니다. 좀 더 정확히 말하자면, 먼저 클라이언트들 중에서 일부를 임의로 고른 뒤, 해당 클라이언트들에게 서버에 있는 메인 모델을 보냅니다. 그 후, 보내진 메인 모델을 각 클라이언트가 가지고 있는 로컬 데이터를 이용해서 학습을 시킨 뒤, 학습된 weight들을 다시 서버로 보내서 이들의 가중평균을 취해 모델을 새로 업데이트 합니다. 이는 각 클라이언트에서 계산한 gradient의 가중평균으로 메인 모델을 학습시킨다고도 볼 수 있습니다. 여기서 단순한 평균이 아닌 가중 평균을 취할 때는 각 가중치가 클라이언트 별 데이터의 숫자에 비례하도록 설정하고, 그 이유는 클라이언트별로 가지고 있는 데이터의 수가 다를 수 있기 때문입니다. 심지어는, 기존의 머신러닝 모델을 훈련할 때와는 다르게 각 클라이언트의 데이터의 분포는 차이가 많이 나는 편입니다. (셀카는 사람에 따라 당연히 달라지죠?) 그렇기 때문에 단순한 평균보다는 가중평균을 취하는 것이 좀 더 좋은 성능을 보일것이라고 생각할 수 있습니다. 또한, 전체 클라이언트가 아닌 일부에 대해서만 하는 이유는 효율성 때문인데, 당연한 사실이지만 클라이언트가 매우 많은 경우에는 모든 클라이언트에 모델을 보내고 학습시킨 뒤 학습된 weight을 다시 서버로 받아오는것은 통신에 대한 비용이 너무 오래 걸릴 수 있습니다. 알고리즘으로 나타내면 아래와 같습니다.

이렇게 하면, 클라이언트가 가지고 있는 데이터를 서버로 보낼 필요 자체가 없어지고, 모델 parameter의 gradient만 전송하기 때문에 데이터의 유출의 위험이 훨씬 줄어들게 됩니다. (뒤에서 설명하겠지만, 완전히 없어지지는 않습니다.) 여기에 덤으로, 데이터를 모두 서버로 보내서 서버에서 모델을 학습시키는 것과 비교해서, 클라이언트로 모델을 보내 학습시키게 되면 통신 비용도 줄어들게 됩니다. 원 논문에서는 MNIST와 Shakesphere와 같은 벤치마크 데이터셋에 대해서 여러가지 셋팅으로 실험을 했는데, Federated Learning에 대해서 설명하는 구글의 블로그 글에 따르면 구글 키보드의 추천 알고리즘의 개선에도 실제로 이용되고 있다고 합니다. 그 이외에도 이후에 의료 데이터나 금융 데이터, IoT와 같은 private한 real-world 데이터에 Federated Learning을 적용한 여러 연구들이 나왔습니다. 또한, gradient를 aggregate할 때 단순히 weighted sum을 취하는 것보다 클라이언트 별 시스템과 데이터의 heterogenity에 좀 더 robust한 FedProx와 같이 성능 자체를 개선하는 연구들도 있습니다.
그렇다면 Federated Learning은 정말로 안전할까요? 꼭 그렇지만도 않습니다. 먼저, federated learning이 안전한 이유가 데이터를 직접 보내는 것이 아닌 gradient만 서버로 보내기 때문이라고 했는데, Deep Leakage from Gradients라는 제목의 논문에서는 gradient를 가지고 역으로 데이터를 복원하는것이 가능하다는 것을 보였습니다. 아이디어 자체는 간단한데, dummy 입력 데이터를 만든 뒤 이 입력에 대한 현재 모델의 gradient를 계산하고, 이 gradient가 목표하는 gradient에 가까워지도록 데이터 자체를 update하는 것 입니다. 또한, local model들을 통합해서 global model을 업데이트 하기 때문에 클라이언트가 자신의 local model에 모델에 대해서 adversarial 데이터를 넣어줌으로써 모델의 성능을 낮추는 poisoning attack과 같은 방법도 있습니다. 물론 창이 있으면 방패가 있듯이 이를 막으려고 하는 연구 또한 당연히 진행된 바 있습니다 (adversarial training을 이용합니다).
이번 포스팅에서는 Private ML의 대표적인 방법 중 하나인 Federated Learning에 대해서 알아보았습니다. 보기에는 안전해 보이지만 완벽하지만은 않다는 것도 알아보았고, 앞으로 개선할 점도 많아보입니다. 다음 포스팅에서는 차분 프라이버시(Differential Privacy)에 대해서 소개하도록 하겠습니다.
'Machine Learning & Deep Learning > Privacy Preserving ML' 카테고리의 다른 글
| Privacy Preserving Machine Learning (3) - Homomorphic Encryption (1) | 2021.06.16 |
|---|---|
| Privacy Preserving Machine Learning (2) - Differential Privacy (0) | 2021.06.13 |

