
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Deep learning
- 자연어처리
- NLP
- Natural Language Processing
- Pre-training
- 머신러닝
- Model Compression
- Homomorphic Encryption
- 동형암호
- AI
- Github Copilot
- Private ML
- GPT
- Transformer
- Computer Vision
- matrix multiplication
- attention
- Language Modeling
- math
- Residual Connection
- 표현론
- Knowledge Distillation
- ICML
- 딥러닝
- Machine Learning
- Knowledge Tracing
- KT
- Data Augmentation
- bert
- Copilot
- Today
- Total
Anti Math Math Club
Multiplying Matrices Without Multiplying 본문
Multiplying Matrices Without Multiplying
seewoo5 2021. 9. 11. 16:44오랜만에 논문 리뷰 글을 쓰네요. 페이스북을 하다가 도저히 지나칠 수 없는 제목의 논문을 발견해서 읽어보았습니다. 제목은 Multiplying Matrices Without Multiplying, 즉 곱하기 안쓰고 행렬 곱하기인데, 이게 뭔 개소린가 싶어서 abstract를 읽어보니 (결과만 보면) 100배정도 더 빨라졌다고 하여 좀 더 자세히 읽어보았습니다.
이 논문에서의 문제 상황은 정말 일반적인 두 행렬을 곱하는 상황이 아닌, 조금 더 특수하지만 그래도 머신러닝을 하다보면 많이 접할 수 밖에 없는 상황을 가정합니다. 그리고 정확한 곱을 계산하는게 아닌 approximate matrix multiplication을 다룹니다(가장 대표적인 approximate matrix multiplication 알고리즘으로는 row-rank로 근사하는 PCA가 있죠). 두 행렬 A, B를 곱한다고 할 때, A는 일종의 model의 input에 대응되는 행렬로써 N by D행렬이고 각각의 D-dimensional row vector가 하나의 input (feature vector, embedding vector 등)을 의미합니다. 즉, 랜덤하게 생성된 행렬이 아니라 행렬의 각 row vector가 어떤 특정한 distribution을 따르는 상황을 가정하는것이죠. B는 model의 parameter (weight)이라고 생각하면 되는데, D by M 행렬로 각각의 column vector가 각 class에 대응되는 weight vector를 의미합니다. 그렇기 때문에 B는 고정된 행렬이라고 생각합니다. 예를 들어, classification을 하는 상황에서는 마지막 linear layer의 input이 A, weight이 B이고 이때 M은 class의 갯수가 됩니다.
그러면 이 경우에 어떻게 계산을 빨리 할 수 있을까요? 이 논문에서 제안하는 MADDNESS(Mult-ADDtioNlESS)라는 방법은 기존에 있던 vector quantization과 product quantization에서 encoding을 K-means clustering 대신 balenced binary tree를 이용한 locality sensitive hashing을 써서 성능을 향상시켰습니다.
먼저, 논문의 기반이 되는 product quantization에 대해서 간단하게 설명하자면 다음과 같습니다. 먼저 A의 row vector의 분포를 학습할 수 있는 일종의 training set에 해당하는 행렬 \tilde{A}가 있다고 가정하고, 여기에 K-means clustering을 적용해서 여러개의 cluster와 각 cluster에 대응하는 center(prototype이라고 부릅니다)를 학습합니다. 그리고 이 center들과 B의 column vector들의 곱을 미리 계산을 해 놓아서 일종의 table을 만들어 놓습니다. 그 후에 실제 input matrix A와 B를 곱할 때 input A의 row vector를 특정 cluster의 center로써 근사한 뒤(이를 A의 encoding이라고 부릅니다) 해당되는 pre-compute된 테이블의 값을 가져와서 결과를 얻는 방식입니다. 여기서 clustering을 할 때 전체 차원을 C개의 subspace로 나눈 뒤 각각에 대한 K-means clustering을 함으로써 조금 더 정확한 근삿값을 얻을 수 있습니다. C가 크면 클수록 좀 더 정확한 결과를 얻는 대신 속도 개선이 더뎌질 것이고, C를 작게 잡으면 속도면에서 좀 더 이득을 보겠지만 정확도를 더 많이 포기하게 됩니다.
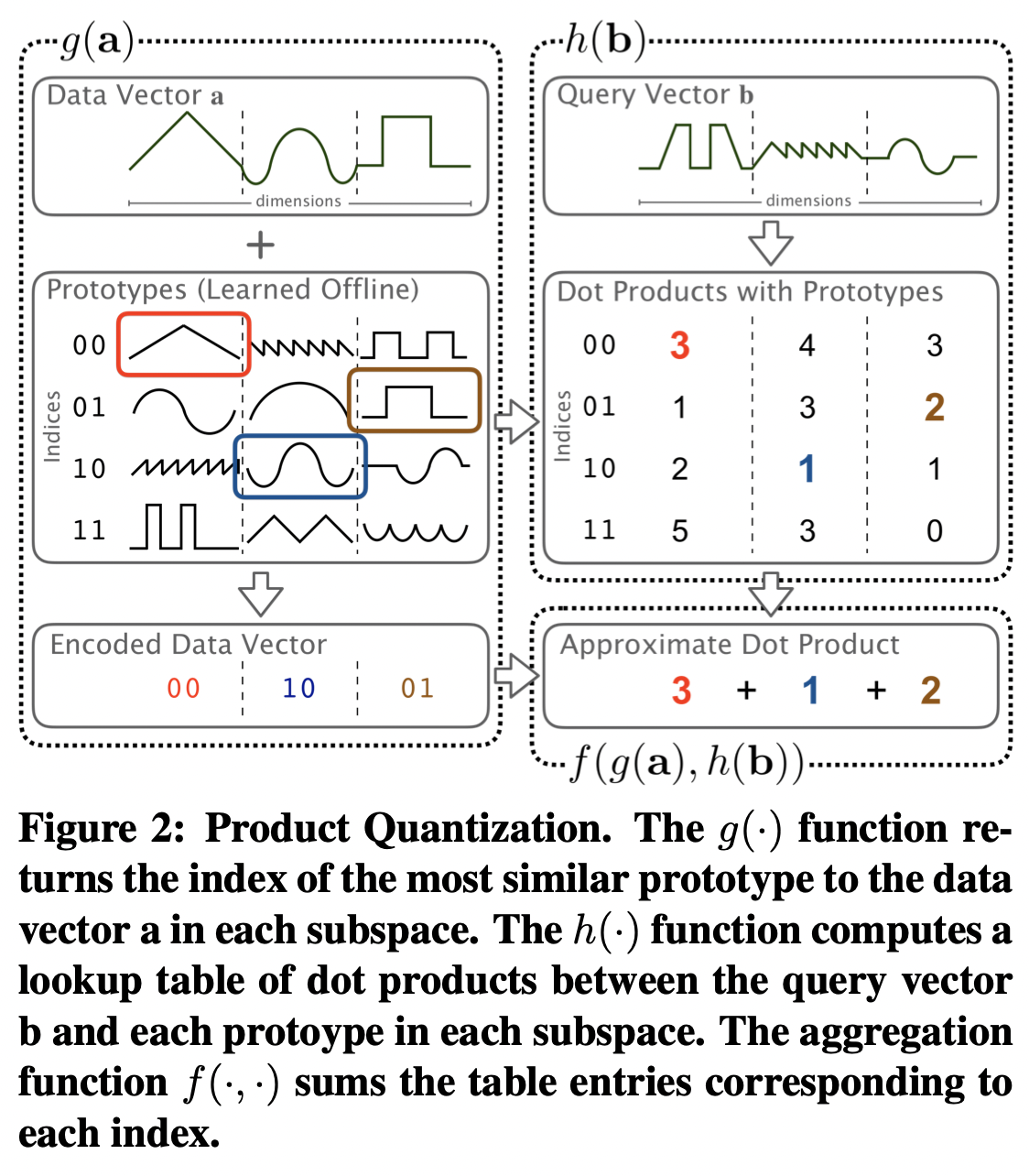
하지만 이 방법은 D(input vector dimension)가 N, M에 비해 많이 작은 경우에 성능 향상이 큰데, 실제 분류 문제를 푸는 상황을 생각해보면 오히려 class의 갯수인 M이 D보다 훨씬 작은 경우가 많습니다. 사실 우리가 원하는 알고리즘은 M, D 모두 N에 비해서 많이 작은 경우에 빠르게 작동하는 것이죠. 저자들은 이를 해결하기 위해서 기존의 K-means clustering을 이용한 encoding 대신에 locality-sensitive hasing을 이용한 encoding을 만듭니다. K-means clustering은 A의 row vector와 거리가 가까운 prototype을 선택하는 것이 아니라, 각 row vector를 K개의 bucket중 하나로 hashing하는데, 여기서 비슷한 vector는 hash값 역시 비슷해진다는 가정을 만족하도록 하는것이죠. (이렇게 말하고보니 둘이 별로 차이가 없어보이네요...) 여기서 제시하는 hashing 알고리즘은 balanced binary tree를 이용하는데, training matrix \tilde{A}를 통해서 input vector를 16개의 bucket중 하나로 보내는 depth 4의 binary tree를 구성합니다. binary tree를 만들 때 학습하게 되는건 4개의 split index들과 각각에 대응하는 threshold들인데, 고정된 4개의 split index들에 대해서 각 entry가 threshold보다 작은지 큰지를 바탕으로 2^4 = 16개의 가능한 bucket중 하나에 할당하는 것이라고 보면 됩니다. 4라는 숫자가 좀 작다고 생각할 수 있는데, 실제로 저자들이 실험했을 때 index의 숫자 n을 1로 두기만 해도 나쁘지 않은 결과를 얻었고, 4보다 크게 둔다고 해서 이득이 되는게 별로 없었기 때문에 n = 4로 두었다고 합니다.
이렇게 학습된 hashing function은 N by KC 크기의 일종의 prototype-selection matrix G로 볼 수 있는데(이때 K = 16입니다), 여기서 각 bucket에 해당하는 prototype vector으로 구성된 KC by D 행렬 P를 만들 때는 이 두 행렬로부터 기존의 training matrix \tilde{A}를 가장 잘 reconstruct할 수 있도록 합니다. 좀 더 정확히 말하자면, \tilde{A}가 GP에 가까워지도록 P를 고르는데, 이는 least square method에 ridge regression을 적용해서 아래와 같은 식을 통해서 계산합니다. (여기서 \lambda = 1로 두었다고 합니다.)
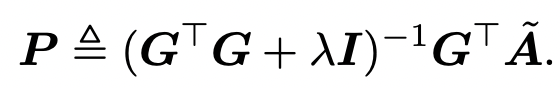
본문의 Theorem 4는 실제로 제시한 방법의 expected error가 아래와 같은 부등식을 만족시키기 때문에 일종의 이론적인 guarantee역시 존재한다는 것을 알려줍니다.

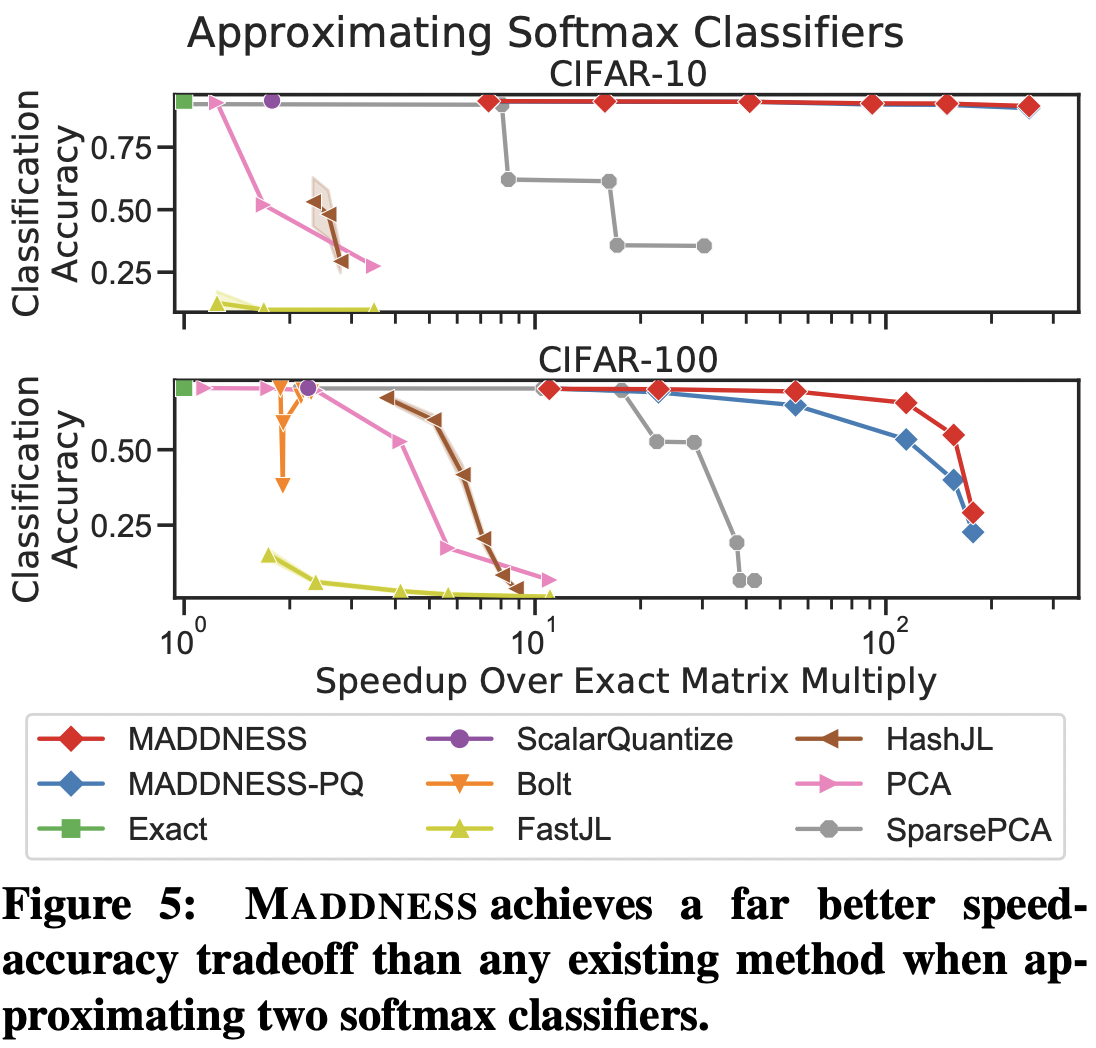
실험 결과는 어떨까요? 아래의 결과는 VGG같은 딥러닝 모델로 먼저 CIFAR-10과 CIFAR-100 이미지의 feature vector를 얻어낸 뒤, 이를 이용해서 linear classifier를 훈련시켜 얻은 결과를 나타냅니다. 그래프에서 바로 볼 수 있듯이, 속도를 높일 수록 다른 matrix multiplication algorithm들의 경우 accuracy가 현저하게 감소하는 반면에, MADDNESS는 속도를 100배까지 높여도 accuracy가 크게 감소하지 않은 것을 볼 수 있습니다. 그 외에도 kernel based classification이나 image filtering등 조금 더 극단적인 상황에서도 MADDNESS가 다른 baseline들에 비해서 더 좋은 결과를 얻었습니다. (이에 대해서는 원 논문을 참고하시길 바랍니다.)
이 외에도 더 low-level에서의 optimization에 대한 내용도 있지만 이는 제가 이해가 부족해서(..) 넘어가도록 하겠습니다.
결론적으로는, 논문 제목을 처음 봤을때의 예상과는 다르게 특정한 상황에서의 행렬곱을 빠르게 근사할 수 있다는 내용이라 약간 실망하긴 했지만, 어떤 면에서는 굉장히 일반적인 상황이기 때문에 좋은 논문이라는 생각이 듭니다. 다만 마지막 linear classifier 뿐만아니라 모든 layer에 대해서 적용할 수도 있을 것 같은데, 이에 대한 실험은 왜 안했을까 하는 의문도 조금 듭니다. (해봤는데 오차가 너무 많이 쌓였다거나...)
'Machine Learning & Deep Learning > Algorithms' 카테고리의 다른 글
| ReZero is All You Need: Fast Convergence at Large Depth (1) | 2021.03.14 |
|---|
