
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 자연어처리
- GPT
- 딥러닝
- Homomorphic Encryption
- Data Augmentation
- KT
- Natural Language Processing
- Residual Connection
- 동형암호
- Transformer
- Copilot
- Knowledge Distillation
- 머신러닝
- bert
- math
- Language Modeling
- 표현론
- NLP
- AI
- ICML
- Knowledge Tracing
- attention
- Computer Vision
- matrix multiplication
- Github Copilot
- Pre-training
- Deep learning
- Private ML
- Machine Learning
- Model Compression
- Today
- Total
Anti Math Math Club
Patient Knowledge Distillation for BERT model compression 본문
Patient Knowledge Distillation for BERT model compression
seewoo5 2021. 3. 25. 23:44이번 포스팅에서는 EMNLP 2019에 accept된 Patient Knowledge Distillation for BERT model compression이라는 논문을 리뷰하도록 하겠습니다.
Knowledge Distillation(KD)이란 커다란 모델(teacher model)의 학습된 '지식'을 작은 모델(student model)로 '증류'하는 방법으로 모델의 크기를 줄이는 것을 말합니다. Hinton의 Distilling the Knowledge in a Neural Network라는 논문에서 처음 제안되었는데, 다음과 같은 순서로 진행합니다.
- 먼저 teacher model을 학습시킵니다.
- student model을 학습시킬 때, loss를 실제 학습에 사용되는 loss(예를들어, BCE loss나 L2 loss등 예측을 잘 하기 위해서 줄이고자 하는 loss를 말합니다)와 더불어서 student와 teacher의 예측의 차이를 줄이는 loss(보통 KL divergence나 BCE loss를 사용하는 듯 합니다.)를 동시에 minimize하도록, 즉 둘의 합(혹은 linear combination)을 실제 학습하는 loss로 두고 student model을 학습시킵니다.
이렇게 되면, teacher model은 일종의 soft label을 만들어내는 역할로써 작용하고, 일반적으로 KD를 이용하면 student model만 학습시키는 것 보다 성능이 높아진다고 알려져 있습니다. 당연히 Computer Vision 뿐만 아니라 다른 task, 특히 NLP에서도 KD를 적용하는 시도들이 많이 있었고, 가장 대표적인 것이 바로 DistilBERT입니다. 이름에서 알 수 있듯이, BERT에 KD를 적용했는데, BERT-base(layer 12개)보다 절반정도 크기의 작은 모델로(layer 6개) BERT-base의 97%정도의 성능을 보이는 모델을 만들었습니다.
이번에 소개하려는 논문(Patient Knowledge Distillation, PKD)는 DistilBERT와 거의 같은 시기에 나와서 아쉽게도 서로에 대한 비교 실험이 딱히 나와있지는 않습니다(참고로 DistilBERT는 2019년 NeurIPS workshop에 accept이 되었습니다). 그래도 PKD가 단순한 KD에 비해서 뭐가 다르고, DistilBERT와는 어떤 차이가 있는지도 뒤에서 짚고 넘어가겠습니다.
Knowledge Distillation and Patient Knowledge Distillation
앞에서 언급했듯이, KD에서는 기존에 사용하는 loss와 더불어 student model의 prediction을 teacher model과 가까워지도록 하는 loss를 동시에 minimize하게 됩니다. PKD에서는 전자의 경우 pre-training을 추가적으로 하지 않고 target task에 바로 훈련을 시키며, classification의 경우 아래와 같은 cross-entropy loss를 사용합니다.

Teacher와 student를 비교할 때도 cross-entropy loss를 사용하는데, 아래와 같습니다.

여기서 P^t와 P^s는 각각 teacher와 student의 prediction을 의미합니다. 여기서 teacher model의 prediction을 계산할 때 그대로 사용하는 것이 아니라 Temperature Parameter T를 도입하여 다음과 같이 soft label을 만듭니다.
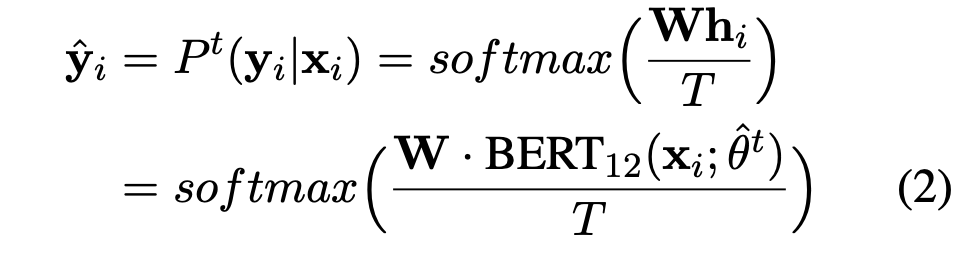
T는 hyper-parameter인데, T의 값이 크면 클수록 prediction의 분포가 uniform해지고, 작을수록 더 sharp해집니다. 즉, teacher의 label을 얼마나 믿을것이냐를 조절하는 역할을 합니다.
PKD의 핵심은 여기에 추가적으로 "patient"한 knowledge distillation을 위한 loss를 하나 더 추가하는 것 입니다. 바로 student model과 teacher model의 hidden state vector들 역시 가까워지도록 하는 것인데, 다음과 같은 loss를 이용합니다.
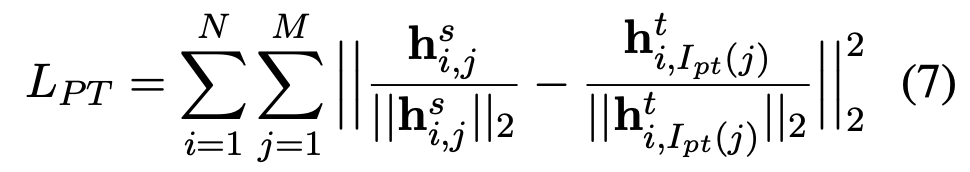
여기서 주의할점은 student와 teacher의 layer의 숫자가 다르다는 것인데, layer별 output이 일대일 비교가 불가능한 상황에서 어떻게 loss를 계산한다는 것일까요? 식에 있는 pt(j)가 바로 student의 j번째 layer의 output vector와 비교할 layer를 대응시켜주는 함수인데, 논문에서는 두가지 전략을 제안합니다.
- PKD-Skip: 일정 간격으로 뛰어넘으면서 비교합니다. 예를 들어, teacher의 layer가 12개, student의 layer가 6개라면 student의 hidden output vector들 h^s_1, ..., h^s_5를 각각 teacher의 h^t_2, h^t_4, h^t_6, h^t_8, h^t_10과 비교합니다.
- PKD-Last: 가장 위쪽(뒤쪽)의 layer들을 순서대로 비교합니다. 예를 들어서, teacher의 layer가 12개, student의 layer가 6개라면 student의 hidden output vector들 h^s_1 ..., h^s_5를 각각 teacher의 h^t_7, ..., h^t_11와 비교합니다.
두 경우 모두 마지막 layer의 hidden state output은 포함하지 않는데, 그 이유는 이미 마지막 layer의 output에 softmax layer를 통과시킨 prediction을 기존의 distillation loss (L_DS)에서 implicit하게 비교하고 있다고 가정하기 때문입니다. 만약 student model의 layer가 n개라면 결국 n-1개의 layer에 해당하는 hidden state output을 비교한다고 볼 수 있습니다.
최종적으로는 3개의 loss L^s_CE, L_DS, L_PT의 linear combination인 L_PKD
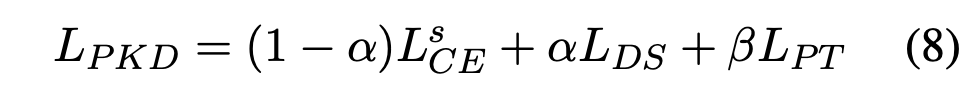
를 가지고 student model을 훈련시킵니다. 여기서 alpha, beta는 hyperparameter입니다.
DistilBERT의 경우에는 downstream task에 바로 훈련시키는게 아니라, student model에 대한 pre-training을 한번 더 진행합니다. 다시 말해서, student-teacher output 사이의 cross-entropy loss와 더불어서 Masked Language Modeling을 위한 MLM loss를 이용하여 먼저 pre-training을 시킵니다. 여기에 추가적으로 cosine embedding loss라는 것을 사용하는데, 논문에 자세히 나와있지는 않지만 보통 사용하는 cosine embedding loss는 두 latent vector에 대해서 1에서 두 vector의 cosine similarity를 뺀 값으로 정의합니다. (PyTorch의 cosine embedding loss) 이 부분의 역할이 PKD의 L_PT와 비슷한 역할을 합니다. 다만 DistilBERT에서 cosine embedding loss를 정확하게 어떻게 적용하는지 (어떤 layer의 output vector를 비교하는지 등)은 언급하지 않고 있습니다.
Experimental Results
실험은 Sentimental Classification, Paraphrase Similarity Matching, Natural Language Inference, Machine Reading Comprehension의 4가지 종류의 task를 다루었는데, GLUE에 있는 dataset과 더불어 추가적인 몇몇 dataset으로 진행했습니다. (SST-2, MRPC, QQP, MNLI, QNLI, RTE, RACE) Student model을 PKD를 통해서 학습시킬 때, 추가적인 pre-training을 하지는 않았고, layer의 갯수가 3, 6인 크기로 실험을 했습니다(model의 dimension은 768로 동일합니다). 아래의 표를 보면, Knowledge Distillation을 했을 때가 하지 않았을 때 보다 좋았고, PKD를 적용하면 (대부분의 경우) 추가적인 성능 향상이 있음을 보여줍니다. 당연하게도(?) 그냥 BERT-base (BERT-12)에 비해서는 성능이 좋지는 않습니다. (간혹 student model이 teacher model보다 더 좋은 경우도 있지만...)


위의 PKD 결과는 PKD-Skip의 결과인데, PKD-Last와 PKD-Skip을 비교했을 때는 PKD-Skip이 거의 항상 (약간) 좋은 것을 아래 표에서 확인할 수 있습니다. 이에 대한 설명으로 저자들은 PKD-Skip은 low-level부터 high-level의 sementic을 골고루 보는 반면, PKD-last는 high-level sementic의 정보만 distil되기 때문에 상대적으로 다양한 knowledge가 distil되는 전자가 더 성능이 좋게 나타나는 것 이라고 주장합니다.

효율성 면에서는 당연히 모델이 작을수록 paramter도 적고 inference속도도 빨라지는데, 정량적인 수치는 아래 표에 나와있습니다.

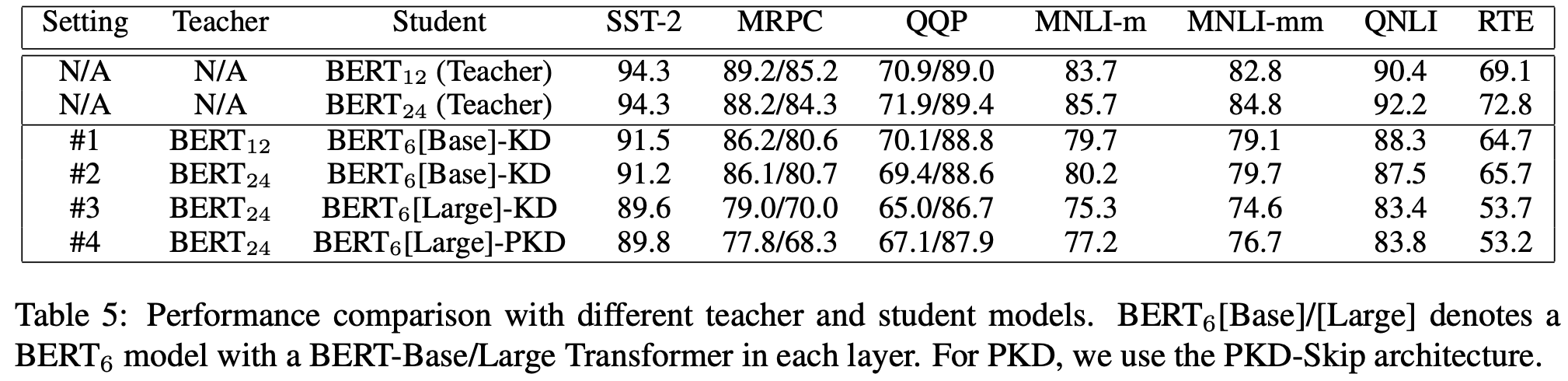
Teacher model의 크기에 따른 실험도 했는데, 아래 표를 보면 꼭 teacher model이 크다고 좋은건 아닌 것을 알 수 있습니다. (#1 and #2) 또한, #1과 #3을 비교했을 때는 BERT-Large로부터 distillation을 했을 때 BERT-Base로부터 distillation을 한 것 보다 더 성능이 안나오는 것을 볼 수 있는데, 저자들은 너무 많이 compress하게 되면 knowledge distillation이 어려워지기 때문이라고 설명합니다. 마지막으로, PKD와 KD를 비교하면 (#3 and #4) PKD의 경우 consistent한 성능의 향상이 있음을 알 수 있습니다.
논문에 대한 개인적인 인상은 아이디어가 간단하고 구현도 어렵지 않을 것 같아서 좋았습니다. 또한, transformer 기반의 모델이면 항상 사용할 수 있는 방법이니 최근에 image에 transformer를 사용하는 여러 연구들(ViT등)에도 써먹어볼 수 있을 것 같다는 생각이 들었습니다. 다만 L_PKD라는 loss 자체가 hidden dimension이 같을 때만 사용할 수 있기 때문에 layer와 dimension을 동시에 줄이고 싶을 때는 쓸 수 없다는 단점이 있는 것을 발견해서 이런 경우에는 방법이 없을까 하는 생각이 들었습니다.



