
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Model Compression
- Natural Language Processing
- NLP
- Private ML
- Residual Connection
- Deep learning
- 머신러닝
- Copilot
- GPT
- Transformer
- KT
- Knowledge Distillation
- Pre-training
- Machine Learning
- math
- ICML
- Computer Vision
- attention
- 자연어처리
- Github Copilot
- Homomorphic Encryption
- 딥러닝
- 동형암호
- Knowledge Tracing
- Language Modeling
- bert
- 표현론
- matrix multiplication
- Data Augmentation
- AI
- Today
- Total
Anti Math Math Club
Extract Training Data from Large Language Models 본문
Extract Training Data from Large Language Models
seewoo5 2021. 1. 11. 02:28이번 포스팅에서는 작년 12월에 arXiv에 등장하여 꽤나 화제가 되었던 논문인 Extract Training Data from Large Language Models라는 논문을 리뷰하도록 하겠습니다.
제목에서 알 수 있듯이 이 논문의 요지는 훈련된 language model로부터 training data를 역으로 추출하는 방법에 대한 이야기를 다루고 있습니다. 여기서 다루는 주제의 중요성은 논문 첫 페이지에 있는 Figure 1로부터 바로 알 수 있습니다.
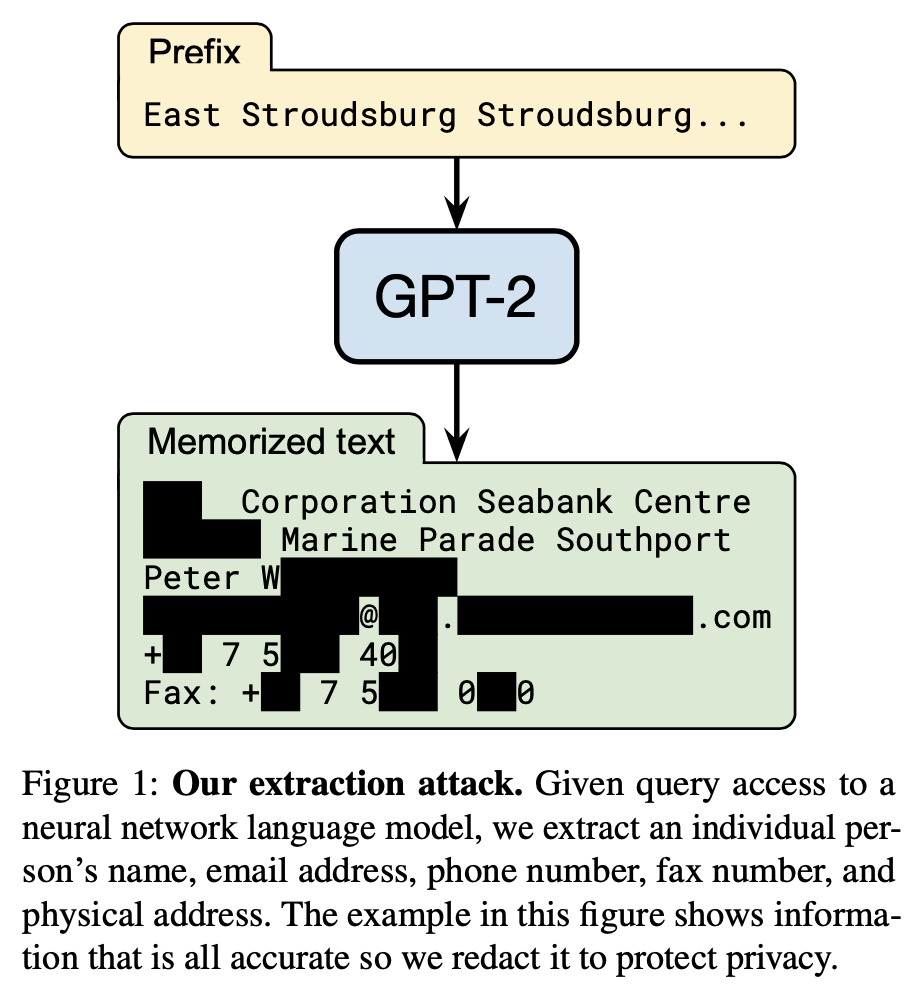
위의 그림에서 볼 수 있듯이 GPT-2에 특정 prefix를 집어넣은 뒤 뒤에 올 token들을 생성하게 되면 training set의 일부인 누군가의 개인정보가 그대로 나올 수 있다는 것입니다. (GPT-2의 traning set은 논문에서 볼 수 있듯이 4500만개의 링크에 해당하는 웹사이트들의 텍스트를 크롤링해서 얻었습니다.)
이렇게 모델로부터 training data를 역으로 추출해내는 연구는 사실 이전에도 많이 있었습니다. 예를 들어, Membership Inference Attacks Against Machine Learning Models라는 논문에서는 주어진 data가 training set에 포함되어있는지 여부를 shadow training (target 모델의 행동을 따라하도록 새 모델을 훈련시키는 것)을 이용한 membership inference를 통해 예측할 수 있다는 것을 보여주었습니다. 이러한 현상이 일어나는 근본적인 이유는 모델이 training set에 overfitting되는 경우, 즉 모델이 정말 training data를 외우는 경우에 나타난다고 생각할 수 있습니다. 다시 말해서, overfitting이 일어나지 않은 모델의 경우 이런 문제가 일어나지 않는다는 것이죠. 그렇다면, 요즘 NLP의 트렌드인 커다란 트랜스포머 계열의 모델들(BERT, GPT등)은 어떨까요? 논문의 저자들이 GPT-2 논문 저자들에게 물어봤을 때, GPT-2 XL (parameter 15억개)의 경우 위에서 언급한 웹사이트 데이터(40GB)에 대해서 12 epoch정도 훈련시켰는데, train loss가 test loss에 비해서 10%정도 작았다고 합니다. 이정도면 overfit이라고 보기는 어렵죠.
이 논문의 주장은 이러한 large-scale language model에서도 (overfitting이 일어나지 않았음에도 불구하고) training data를 추출할 수 있다는 것입니다. 사실, 위에서 언급한 train loss와 test loss의 비교는 평균 loss를 비교한 것이기 때문에, 각 example에 대한 loss역시 작다고 할 수는 없습니다. 그리고 이러한 memorized example을 뽑아내는 방법 역시 원론적으로는 간단한데, 바로 생성된 sentence 중에서 likelihood가 높은 것을 뽑으면 됩니다. likelihood가 높다는 것은 모델이 확신을 가지고 생성을 했다는 것이고, 이는 모델이 해당 example을 외웠을 가능성이 크다고 볼 수 있기 때문입니다. 물론 이것만으로 Figure 1과 같은 example들을 무진장 뽑아낼 수 있다면 재미가 좀 떨어지겠죠? 실제로 단순히 GPT-2에서 확률적으로 하나의 token씩 decoding해서 만드는 방법으로는 원하는 결과를 얻기 힘들다고 합니다. 그렇다면 어떻게 했을까요?
그 방법을 설명하기 이전에, 모델로부터 특정 example을 추출한다는 것과 모델이 특정 example을 외웠다라는 것을 어떻게 정의할 수 있을지 생각해봐야 합니다. 논문에서는 다음과 같이 정의합니다.
Definition 1. (Model Knowledge Extraction) 문자열 s가 language model f_theta로부터 추출될 수 있다는 것은 어떤 prefix c가 있어

가 됨을 말합니다. (f_theta의 output은 likelihood입니다) 여기서 모든 길이 N의 문자열에 대한 최댓값을 구하는 데에 걸리는 시간은 N에 대해서 exponential하게 증가하기 때문에, greedy sampling이나 beam search같은 다른 방법으로 만들어내는 것으로 대체해서 생각할 수도 있습니다.
Definition 2. (k-Eidetic Memorization) 문자열 s가 language model f_theta에 대해서 k-eidetic memorized (k는 1 이상의 정수) 되었다 라는 것은 s가 f_theta로부터 추출될 수 있고 s가 training set에서 최대 k번 등장하는 경우를 말합니다.
1-eidetic memorized된 문자열은 training set에 딱 한번 등장함에도 불구하고 모델로부터 얻어낼 수 있는, 말 그대로 한번 보고 외운 경우라고 생각할 수 있습니다. 또한, 모델로부터 추출될 수 있는 문자열이라고 할지라도 k가 매우 큰 경우, 즉 training set에 많이 등장하는 경우는 큰 문제가 되지 않을 수 있습니다. (language model이 "I love you"라는 문장을 생성할 수 있는 것이 privacy의 문제를 일으키지는 않죠.) 하지만, training set에 딱 한번 등장한 전화번호, 주민번호같은 개인 정보를 추출할 수 있는 경우(k=1) 문제가 될 수 있고, 논문에서 다루고자 하는 부분도 k가 작은 경우들 입니다.
그렇다면 이제 이런 memorized example을 뽑아내는 방법에 대해서 알아봅시다. 가장 간단한 방법이면서 논문의 저자들이 처음 시도했던 방법은 문장을 start token부터 시작해서 probabilistic하게 생성해내고, 그 중에서 likelihood가 큰 것을 추려내는 방법입니다. GPT-2 XL을 기반으로 각 example마다 256개의 token을 생성했고, 각 token마다 top-40개의 후보들 중에서 normalized probability에 따라서 sampling하는 방법을 이용하여 총 200000개의 example을 만들어냈습니다. 그 결과, 실제로 모델이 외운 example들이 있었는데, MIT public license나 Vaughn Live라는 스트리밍 사이트의 유저 가이드와 같은 것들입니다. 또한, twitter 아이디나 메일주소와 같은 개인정보들도 외우는데에 성공하였습니다. 하지만, 이런 예시들은 대부분 k가 큰 경우, 즉 training set에 많이 등장한 경우였습니다. 이런 단순한 방식의 접근에는 크게 두가지 문제점이 있었는데, 하나는 200000개의 example들 중에서 중복되는 것이 상당했고, 또 하나는 likelihood가 큰 example중에서 실제로 training set에 등장하지 않는 것들이 많았습니다. 특히, 후자의 경우에는 이 논문에도 언급되는 문제인 같은 문장이 반복되는 example이 자주 나왔다고 합니다.
이를 개선하기 위해서, 저자들이 제안한 방법은 1) decaying temperature와 2) conditioning on internet text입니다. Temperature란 softmax 함수의 output을 조절하는 일종의 scaling constant인데 (temperature라는 이름이 붙은 이유는 통계역학에서 왔다고 들은 것 같은데 자세한건 모르겠습니다) 벡터 z = [z_1, ..., z_n]에 대해서 softmax(z)를 실수 t >= 1에 대해서 softmax(z/t)로 바꾸게 되면 t가 커질수록 결과값은 원래의 결과값에 비해서 좀 더 flatten되는, 즉 confidence가 떨어지는 효과를 줍니다. 이를 이용해서, 문장을 생성할 때 초반에는 temperature를 10으로 둬서 좀 더 다양한 token을 뽑을 수 있도록 하고, 그 후에 temperature를 20번째 token까지 1로 낮춰가면서 결과적으로는 문장의 diversity를 높일 수 있게 합니다. 후자의 경우는 GPT-2와 다른 source의 internet text를 conditioning prefix로 둔 뒤에 나머지 문장을 만들어내는 것으로, Common Crawl로부터 얻어진 50MB의 데이터로부터 초기 5~10 token을 가져왔다고 합니다.
또한, language model이 만들어낸 example 중에서 likelihood는 높지만 실제로 존재하지 않거나 (앞에서 언급했듯이 똑같은 문장이 반복되는 경우) 혹은 1~100의 숫자가 차례대로 나오는 것과 같이 training set에 많이 존재하면서 unintersting 한 경우를 선택하는 문제를 해결하기 위해서 GPT-2의 likelihood 이외에도 총 5개의 추가적인 metric을 제안합니다. 이는 기본적으로 다른 language model의 likelihood와 비교하는 것인데, repeated sentence와 같은 example이 아닌 좀더 희귀한 (우리가 원하는) memorized example을 찾기 위해서는 다른 language model에 비해서 likelihood가 비정상적으로 높은 것을 고르자는 전략입니다. 이를 위해서 GPT-2 small (1.2억개), GPT-2 medium (3.5억개), 그리고 zlib compression과의 likelihood를 비교하거나, lower-cased text 혹은 sliding window를 이용합니다. lower-cased text와의 likelihood 비교는 특정한 방식으로 대문자가 사용되는 example을 찾기 위함이고 (뉴스나 논문의 제목처럼 모든 단어가 upper case로 시작되는 경우 등), sliding window는 non-memorized sentence 사이에 끼어있는 memorized text를 걸러내기 위함입니다.
이렇게 원래의 baseline 방법을 포함해서 총 3가지의 문장 생성 방법과 총 6가지의 metric이 있는데, 이를 바탕으로 다음과 같이 memorized example의 후보를 추려냅니다. 먼저 각 3가지 방법에 따라서 총 20000개의 example을 만들고, 각 6개의 metric별로 정렬하여 (trigram을 바탕으로) 중복을 제거한 뒤 top 100개씩 뽑아서 총 1800개의 memorized example의 후보를 얻습니다. 그 후, 각각의 example을 인터넷 검색(!)을 통해서 실제 training set에 존재하는지를 확인합니다. (실제로 구글링으로 확인된 후보들이 training set에 포함되어 있다는 것을 GPT-2 저자들로부터 확인했다고 합니다.) 그림으로 정리하면 아래와 같습니다.

결과는? 1800개중 무려 604개가 unique memorized example, 즉 1-eidetic memorized example에 해당했다고 합니다. 아래의 Table 1은 category 별 갯수를 나타낸 것인데, 진한 글씨로 표시한 78개는 개인정보에 해당하는 example입니다. 또한, 문자 생성 방법과 metric에 따른 18개의 configuration 각각에 대한 결과를 봤을 때 prefix가 있는 경우 (internet text) 그렇지 않은 경우에 비해서 특히 효과적이었으며, 가장 좋은 configuration (Internet, zlib)의 경우 67%의 true positive rate를 보여주었습니다. 실제 예시로는 base-64 encoded URL, 프로그래밍 코드, UUID등이 있었고, 지금은 고쳐지면서 사라진 error log과 같은 것들도 있었다고 합니다. 지워져야할 데이터를 모델이 기억한다는것도 문제를 야기할 수 있는 부분입니다.


이 외에도 여러가지 variation들을 실험했는데, 256보다 더 긴 문장을 beam search로 생성했을 때 Github에 있는 1450줄의 특정 코드를 통째로 외우는 경우도 있었고, pi의 자릿수를 외우는 실험에서는 context에 따라서 그 결과가 크게 달라졌다고 합니다. ("3.14159"를 prefix로 줬을때는 25자리까지 맞게 생성한 반면, "pi is 3.14159"를 prefix로 줬을 때는 무려 799자리까지 만들어냈다고 합니다.) 또한, 모델의 암기 능력과 특정 example이 training set에 등장하는 횟수, 모델의 크기와의 관계에 대해서 질문을 할 수 있는데, reddit url을 가지고 실험한 결론은 1) 모델의 크기가 클수록 memorization하는 양이 더 많아지고 2) 모델이 외우기 위해서 필요한 등장 횟수는 생각보다 크지 않다(33회)는 것 입니다.
그렇다면, 이러한 이슈를 해결하는 방법은 무엇일까요? 가장 떠올리기 쉬운 방법은 바로 training set에서 private한 data를 없애는 것 입니다. 이와 더불어서 training set 자체를 잘 선정하는것도 중요하게 됩니다. 개인정보로 가득한 dataset으로 훈련시키면 안되겠죠. 그 외에도 저자들은 Differential Privacy를 기반으로 모델을 훈련시킨다던지, Fine-tuning을 통해 training data를 잊게 만드는 등의 방법들을 제안합니다. 어찌되었던간에, 이 논문은 모델을 키우는 것이 대세인 요즘 NLP 연구에서 고려해야할 중요한 포인트를 짚어줬다는 생각이 듭니다.
'Machine Learning & Deep Learning > Natural Language Processing' 카테고리의 다른 글
| Patient Knowledge Distillation for BERT model compression (0) | 2021.03.25 |
|---|---|
| Improving BERT with Syntax-aware Local Attention (0) | 2021.01.22 |
| F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax (0) | 2020.12.14 |
| Data Augmentation in Natural Language Processing (0) | 2020.07.11 |
| Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (0) | 2020.07.05 |



