
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Pre-training
- 동형암호
- 딥러닝
- attention
- NLP
- Computer Vision
- Knowledge Tracing
- GPT
- 자연어처리
- Knowledge Distillation
- Transformer
- ICML
- Machine Learning
- KT
- Natural Language Processing
- 표현론
- Model Compression
- math
- matrix multiplication
- Copilot
- 머신러닝
- AI
- Language Modeling
- Residual Connection
- Private ML
- Deep learning
- Data Augmentation
- Homomorphic Encryption
- bert
- Github Copilot
- Today
- Total
Anti Math Math Club
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning 본문
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning
seewoo5 2020. 9. 19. 19:41이번 포스트에서는 (제가 알기로는) Consistency Regularization이 처음 소개된 논문인 Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning이라는 논문에 대해서 알아봅시다.
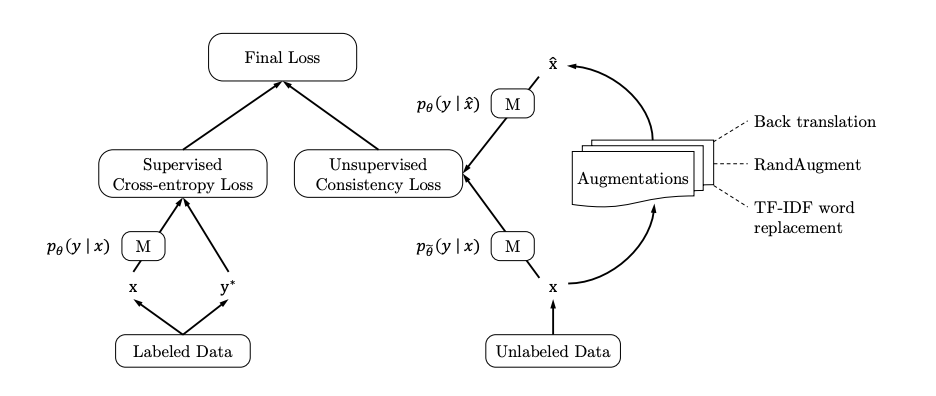
Consistency Regularization이란, 간단히 말해서 모델의 Input에 augmentation을 가해서 새로운 input을 만들었을 때, output (prediction)이 별로 변하지 않아야 한다는 가정을 바탕으로 모델을 regularize하는 방법 입니다. 예를 들어서, 이미지를 분류하는 CNN이 하나 있을 때, 기존에 있던 강아지 사진을 뒤집거나 돌리는 등의 작업을 해서 새로운 강아지 이미지를 만들었을 때, 모델의 강아지에 대한 예측값 (마지막 layer의 확률값)이 크게 변하지 않게 해주는 것 입니다.
이렇게 모델을 훈련시키게 되면 모델이 좀 더 robust해진다는 장점도 있지만, 또 한가지는 consistency regularization은 label이 없는 이미지를 활용할 수도 있게 해 줍니다. 다시 말해서, semi-supervised learning을 가능하게 해 주는 한가지 접근이라고 할 수 있습니다. 알다시피, label을 다는 것은 사람의 힘이 필요한 굉장이 cost가 많이 들어가는 작업이며, label자체가 없는 이미지들을 활용할 수 있다면 모델을 훈련시킬 때 사용할 수 있는 데이터의 숫자가 훨씬 증가하기 마련이며 모델의 generalizability도 더욱 좋아지게 됩니다.
그렇다면 구체적으로 consistency regularization이 어떻게 작용하는지 알아봅시다. 한마디로 요약하자면, 각 training sample을 여러번 augmentation을 한 input들에 대한 output이 크게 변하지 않도록 하는 loss를 이용하는 것 입니다. 총 N개의 training sample x_1, ..., x_N이 있고 이들 각각에 대해서 n번의 augmentation T^1, ..., T^n을 가해서 모델에 넣어주었을 때, 그때의 output (prediction distribution)의 pairwise difference를 줄이는 다음과 같은 loss

를 바탕으로 모델을 훈련시키면 됩니다. (TS는 Transformation Stability의 약자입니다.) 위의 식에서 f^j는 j번째 pass에 대응되는 모델인데, 같은 모델 & 같은 입력이라고 하더라도 dropout / random pooling 등을 적용하게 되면 그 때 마다 output이 달라질 수 있기 때문에 f^j들은 실제로 모두 다른 모델이 됩니다. 이 loss는 서로 다른방식으로 augment된 두 input에 대한 output을 비교하기 때문에, input의 label 유무는 중요하지 않고 따라서 label이 없는 이미지들을 활용할 수 있게 됩니다.
여기에 추가적으로, Mutual-Exclusivity Loss를 이용하는데, 이는 Mutual Exclusivity Loss for Semi-Supervised Deep Learning라는 논문에서 처음 소개된 것으로 모델의 prediction이 좀 더 확신을 가지도록 bias를 주는 loss입니다. 다시 말해서, 각 class에 대한 확률값이 하나만 1에 가깝고 나머지는 0에 가깝도록 해 주는 loss로써 다음과 같이 정의합니다.

f_k^j(x_i)는 x_i가 k번째 class에 속할 확률의 모델의 예측값이며, 큰 괄호 안에 있는 값은 하나의 값이 1이고 나머지가 0일 때 -1로 최솟값을 갖는 것을 확인할 수 있습니다. 이는 이 논문에 소개된 Entropy Minimization과 비슷한 효과를 주는 loss로 볼 수 있습니다. 이 역시 label이 존재하지 않는 샘플들에 대해서 계산할 수 있습니다. 최종적으로는 기존 supervised learning에서의 Cross-Entorpy loss에 위의 consistency & mutual-exclusivity loss를 모두 더해서 한번에 모델을 훈련시킵니다.
실험은 MNIST, CIFAR, SVHN, ImageNet 등 자주 쓰이는 benchmark 데이터에 대해서 진행되었습니다. MNIST의 경우, 각 class마다 10개씩 총 100개의 이미지를 랜덤하게 골라서 작은 training set을 만든 뒤 이를 label이 있는 train set으로 생각하고 여기서의 supervised learning과 semi-supervised (with consistency & mutual-exclusivity loss) learning을 비교했을 때 error rate가 크게 감소하는 것을 보였습니다. 이때 data augmentation은 사용되지 않았고, 오로지 모델의 randomness (dropout, random pooling 등)에 의해서만 output이 바뀌는 상황을 가정했습니다.

Consistency Regularization은 이후 MixMatch, Unsupervised Data Augmentation 등의 논문에서도 사용되고 있는데, Contrastive Learning과 더불어서 semi-supervised learning에서 좋은 효과를 보여주는 방법이라는 생각이 듭니다.

'Machine Learning & Deep Learning > Computer Vision' 카테고리의 다른 글
| Generative Pretraining from Pixels (5) | 2020.09.19 |
|---|
