
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- math
- GPT
- Language Modeling
- Private ML
- NLP
- Residual Connection
- 자연어처리
- Pre-training
- 표현론
- Copilot
- 머신러닝
- Computer Vision
- Natural Language Processing
- Transformer
- 딥러닝
- 동형암호
- ICML
- KT
- Deep learning
- Knowledge Tracing
- matrix multiplication
- Github Copilot
- Homomorphic Encryption
- Model Compression
- attention
- AI
- Data Augmentation
- Machine Learning
- Knowledge Distillation
- bert
- Today
- Total
Anti Math Math Club
Generative Pretraining from Pixels 본문
Generative Pretraining from Pixels
seewoo5 2020. 9. 19. 23:38이번 포스팅에서는 ICLR 2020 Honorable Mention Award를 받은 Generative Pretraining from Pixels라는 논문에 대해서 알아보도록 하겠습니다.
Computer Vision에서는 ImageNet을 이용한 pre-training & fine-tuning이 거의 표준으로 자리잡고 있는 반면, NLP에서는 Wikipedia같은 거대한 corpus가 있다고 해도 sentiment나 POS tag같은 label이 붙어 있는 데이터는 많지 않기 때문에 pre-training을 하는 것이 쉽지 않습니다. 하지만, GPT와 BERT를 기점으로 한 self-supervised learning은 이러한 데이터를 활용해서 모델을 똑똑하게 pre-train하는 것을 가능하게 해 주었고, 다양한 task에서 state-of-the-art의 성능을 보여주었습니다. Computer vision에서도 self-supervised의 방식으로 모델을 훈련시키는 접근들이 여러가지 있는데, 이미지의 일부를 잘라내서 그 부분을 예측한다던지, 이미지를 90도, 180도, 270도 회전시키고 얼마나 돌아갔는지를 4-class로 예측한다던지, 이미지 일부의 위치관계를 맞춘다던지 하는 방법으로 접근하였습니다.
그렇다면, GPT나 BERT를 image classification에 사용하는 것이 가능할까요? (대부분의 딥러닝 연구가 Computer Vision에서 영감을 받아서 NLP에 적용하는 것이 많았다는 것을 고려하면, 이는 거꾸로 NLP에서 영감을 얻어 Computer Vision에 적용하는 색다른 접근으로 볼 수 있습니다.) 아얘 GPT처럼 next-pixel prediction을 통해 Transformer를 pre-training하게 되면, image classification에 도움이 되는 좋은 representation을 배울 수 있을까요? BERT의 MLM (masked language modeling)을 적용하는것도 가능하지 않을까요? 이는 누구나 한번쯤 생각해볼만한 아이디어같은데, 이 논문에서는 실제로 이러한 접근이 (엄청난 computational resource를 바탕으로) 가능하다는 것을 실험으로 증명하였습니다.
Transformer는 sequential data를 다루는 모델이기 때문에 이를 사용하기 위해서는 이미지 역시 sequential하게 바꿔줘야 하는데, 아주 단순하게 2D모양의 이미지를 한줄씩 이어붙여서 1D data로 만드는 방법이 있습니다. 이렇게 되면 3 * 224 * 224 pixel의 이미지의 경우 길이 15만의 sequence로 바뀌게 되고, 기존 Transformer는 메모리와 계산 시간이 input sequence 길이의 제곱에 비례하기 때문에 바로 적용하기에는 GPU가 감당하지 못할 수도 있습니다. Sparse Transformer나 Reformer에서는 이러한 O(n^2) bottleneck을 해결하는 효율적인 self-attention 기법들을 개발해서 실제로 괜찮은 image generation을 하는데에 성공했습니다. 물론, auto-regressive하게 픽셀을 하나씩 예측하고 붙여나가는 방법으로 접근하였습니다. 하지만 이 논문에서는 이미지 자체를 32 * 32나 64 * 64의 low-resolution으로 바꿔서 사용하였습니다. 그렇게 하더라도 32*32*3=3072역시 짧지는 않은 길이이기 때문에, 추가적으로 RGB value를 k=512-means clustering을 통해서 새로운 9-bit color palette를 만들어 32*32=1024로 한번 더 줄였습니다.
그 다음은 GPT나 BERT와 다를 것이 없습니다. 위에서 말한 것 처럼 negative log-likelihood loss로 GPT에서는 next pixel을, BERT에서는 masked pixel을 예측하도록 pre-training을 합니다. 이는 CNN과 다르게 이미지가 2D라는 정보를 이용하지 않는다는 특징이 있습니다. 위아래로 붙어있는 pixel이 sequence로 바뀌면서 더이상 붙어있지 않게 되기 때문에 spatial한 정보를 사용하지 않게 되는 것이죠. Fine-tuning시에는 마지막 layer output의 평균을 feature vector로 사용해서 classifier network를 학습시킵니다. 또한, GPT처럼 pre-training에서 사용된 NLL loss를 fine-tuning시에도 loss에 포함시켜서 학습시키는 것이 더 좋은 결과를 보였다고 합니다.
Fine-tuning과 비슷하지만 약간 다른 접근방법으로 linear probing도 있습니다. pre-trained model을 이용해서 input image X에 대한 feature vector f_X를 얻어낸 뒤, (X, Y) 대신 (f_X, Y)를 가지고 linear classifier를 훈련시키는 것 입니다. 어떻게 보면 feature의 quality를 평가하는 것으로 볼 수 있고, fine-tuning은 모델의 마지막 layer의 output을 classifier의 input으로 이용하는 반면, linear probing에서는 중간 layer의 output을 사용하는 것이 더 좋다고 합니다.

여러가지 실험중에서 (제가 생각하기에) 중요한 것 몇가지만 정리하자면, 앞서 말했듯 linear probing에서는 중간 layer의 output을 사용하는것이 가장 좋았다고 합니다. 이는 autoregressive하게 학습하는것과 image classification사이의 관계가 명확하지 않기 때문에, 모델의 최종 output이 classification을 위한 좋은 representation이 아닐 수 있기 때문입니다.

또한, auto-regressive modeling에서의 validation loss와 최종 accuracy 사이의 관계를 봤을 때, 아래와 같이 validation loss가 작을수록, 또한 모델 크기가 클 수록 높은 정확도를 보임을 알 수 있고, 이는 좋은 generative model이 좋은 representation을 준다는 것을 알려줍니다.

마지막으로, BERT의 MLM(여기서는 MPM, Masked Pixel Modeling이라고 하는게 맞겠네요)으로 접근했을때는 linear probing만 했을 때 iGPT에 비해서 성능이 좋지 않았지만, fully fine-tuning을 하게 되면 비슷하거나(CIFAR-10) 약간 더 앞서는(ImageNet) 성능을 보여주었고, fine-tuning시에도 masking을 적용해서 ensemble을 하게 되면 성능이 더 증가하는 것을 확인하였습니다.
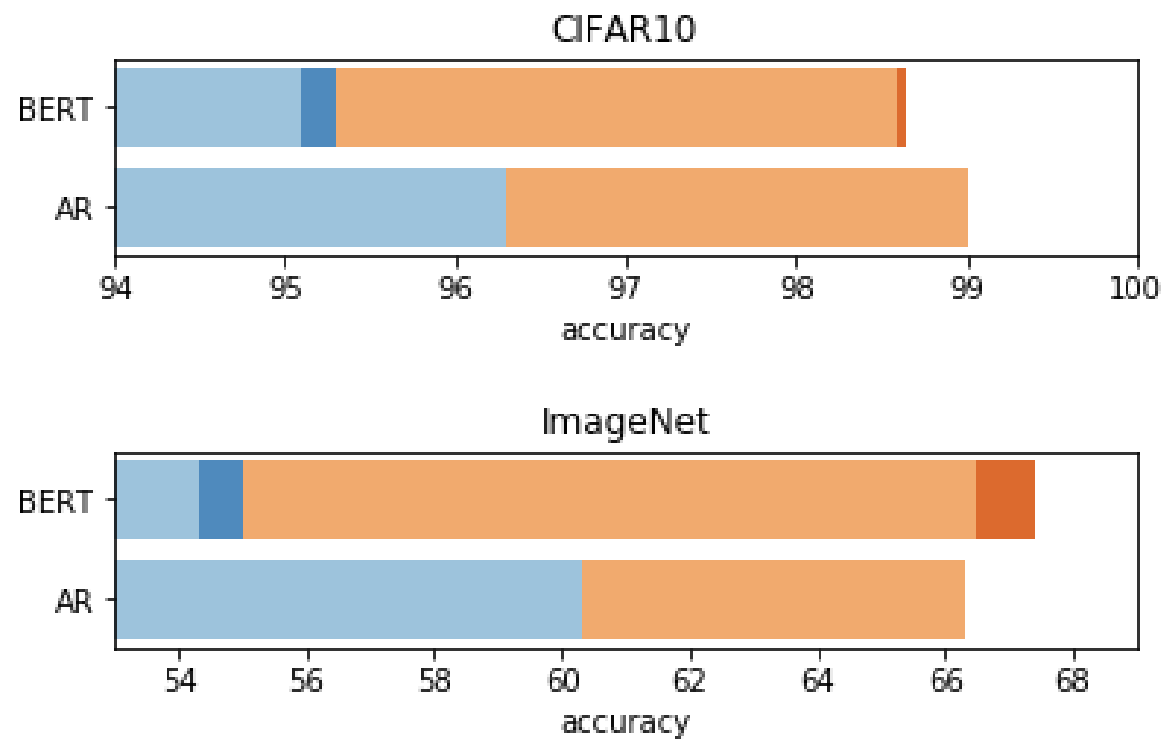
결론적으로, Generative Pre-training이 image classification에서도 좋은 성능을 보인다는 것을 보여준 논문이라고 할 수 있습니다. 한가지 중요한점은, OpenAI에서 나온 논문인데 (2저자가 GPT의 원 저자입니다.), 2048개의 TPU core를 사용했다는 점에서 OpenAI라서 할 수 있는 연구라고 볼 수 있습니다. BERT pre-training처럼 일반인은 실험할 엄두조차 낼 수 없는 연구로써, 모델을 경량화하거나 혹은 좀 더 효율적으로 pre-training을 할 수 있다면 더 많은 사람들이 관심을 가질 수 있는 연구가 되지 않았을까 합니다. (물론 Honorable mention까지 받은 좋은 논문입니다...)
