
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- GPT
- KT
- 표현론
- ICML
- Copilot
- Model Compression
- Deep learning
- math
- 자연어처리
- bert
- 딥러닝
- Natural Language Processing
- Transformer
- Pre-training
- Private ML
- Residual Connection
- Knowledge Distillation
- Data Augmentation
- Homomorphic Encryption
- matrix multiplication
- Computer Vision
- 머신러닝
- attention
- Language Modeling
- Knowledge Tracing
- Machine Learning
- AI
- NLP
- 동형암호
- Github Copilot
- Today
- Total
Anti Math Math Club
F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax 본문
F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax
seewoo5 2020. 12. 14. 00:59이번 포스팅에서는 올해 EMNLP에 나온 F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax에 대해서 리뷰하겠습니다.
Introduction
Text generation이란 말 그대로 문장을 생성하는 task를 말합니다. 대화 시스템, 기계번역, 요약 등 여러가지에 사용되는 NLP의 기본적인 task중 하나라고 생각할 수 있습니다. 기존의 text generation의 대부분은 language modeling, 즉 문장의 분포를 autoregressive하게 모델링하는 방법으로 모델을 훈련시키고, 이때 loss는 negative log likelihood를 사용합니다. 즉, likelihood를 최대화하는 방향으로 모델을 학습시키는 것이죠. 하지만, 이러한 학습법은 좋은 문장을 생성하지 못하는 경우가 많은데, 그 원인으로는 모델 아키텍쳐나 훈련 데이터와 실제 데이터 사이의 간극 등 여러가지가 제시되었습니다. 최근에는 likelihood를 최대화 하는 것 자체가 제대로된 language modeling를 하지 못하게 한다거나 [1], likelihood를 최대화 하는 것이 계속해서 같은 token을 반복하거나 이상한 token을 뱉는 등 실제 인간이 문장을 만드는 과정을 잘 모델링하지 못하기 때문이라고 이야기하고 있습니다 [2].
논문에서는 likelihood를 최대화 하는 방법의 가장 근본적인 이유는 바로 자연어의 token 자체의 불균등함이라고 주장합니다. 영어의 경우 가장 많이 등장하는 단어 100개가 전체 corpus에서 절반 이상을 차지합니다. 이 때문에 maximum likelihood estimator를 사용해서 모델을 훈련시키는 경우 많이 등장하는 단어일수록 더 높은 확률을 할당하는 문제가 생기는 것이죠. [3]
Methods
이러한 불균등함을 해소하기 위해서 논문에서 제안하는 방법은 바로 F^2-Softmax인데, 기존의 language modeling을 두 확률의 곱으로 쪼갠 뒤, 각각을 학습하는 것 입니다. 이를 위해서 먼저 corpus를 각 token의 frequency에 따라서 여러개의 frequency class로 나눈 뒤, 기존의 autoregressive한 language modeling이 학습하는 확률을 아래와 같이 (1) 다음 단어가 속할 frequency class의 분포와 (2) 해당 class에서의 token의 분포 두가지를 이용해서 factorize하는 것 입니다. 식으로 나타내면 아래와 같습니다.

이전에도 softmax를 여러 level로 쪼개는 hierarchical한 접근법은 있었지만 ([4, 5, 6]) 이 연구들은 모두 softmax 자체를 효율적으로 계산하는것이지 데이터의 불균등함을 해결하는것이 목적은 아니었습니다.
아무튼, 이 F^2-softmax에 해당하는 objective는

가 되고 (여기에 -를 붙인 것이 loss가 됩니다) 각각의 확률을 frequence class와 vocabuluary에 해당하는 단어 벡터 u^c, o^x에 대해서,

위와 같이 softmax로 모델링합니다. 여기서 h_{t-1}은 context x_{<t} = (x_1, ... , x_{t-1})에 해당하는 hidden state vector입니다. 여기서 두번째 p_2의 경우 전체 corpus가 아닌 특정 class내에서의 분포를 예측하기 때문에, 전체 corpus에 대해서 확률을 뽑는 것 보다 좀 더 imbalance가 줄어든 값이 나오게 됩니다.
그렇다면 class는 어떻게 쪼갤까요? 이 과정이 Maximum Efficienty Maximization, 즉 MefMax입니다. 결국 목적은 확률이 최대한 균등하게 나오도록 쪼개는 것인데, 각 class들의 distribution과 각 class내의 token들의 distribution을 모두 균등하게 만드는 방향으로 class를 나누는 것을 목표로 합니다. 즉, uniform한 정도를 나타내는 척도를 U(C)라고 한다면, 아래의 함수를 maximize하는 C'을 찾는 것 입니다.

여기서 U는 Shannon의 entropy를 사용하는데, Shannon의 entropy는 sample의 갯수에 영향을 받기 때문에 normalized entropy, 즉 efficiency를 사용합니다.
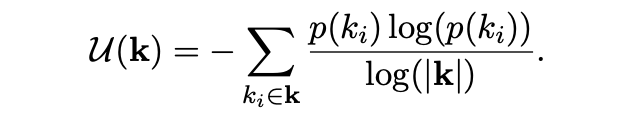
결국 위의 mean efficiency를 최대화 하는 class의 partition을 찾는 것이 목표인데, 모든 경우를 다 해보는 것은 corpus 크기에 대해서 exponential한 시간이 들기 때문에 불가능합니다. 이를 해결하기 위해서 greedy한 접근 방법을 사용하는데, 이는 mean efficiency가
각 class의 frequency가 같을 때 최대화 된다는 가정 하에 아래와 같은 알고리즘에 따라서 class boundary를 찾습니다. 즉, class number K를 먼저 정한 뒤, 각 class의 frequency의 합이 1/K가 되도록 boundary를 정하는 것 입니다. 이렇게 하면 전체 corpus의 크기에 linear한 시간 안에 해를 구할 수 있습니다.

decoding할 때에도 마찬가지로 class를 먼저 뽑고 그 안에서 token을 뽑게 되는데, 여기서 class를 뽑는 것은 deterministic과 stochastic한방법 두가지가 모두 가능합니다. 지금까지의 과정을 그림으로 나타내면 아래와 같습니다.
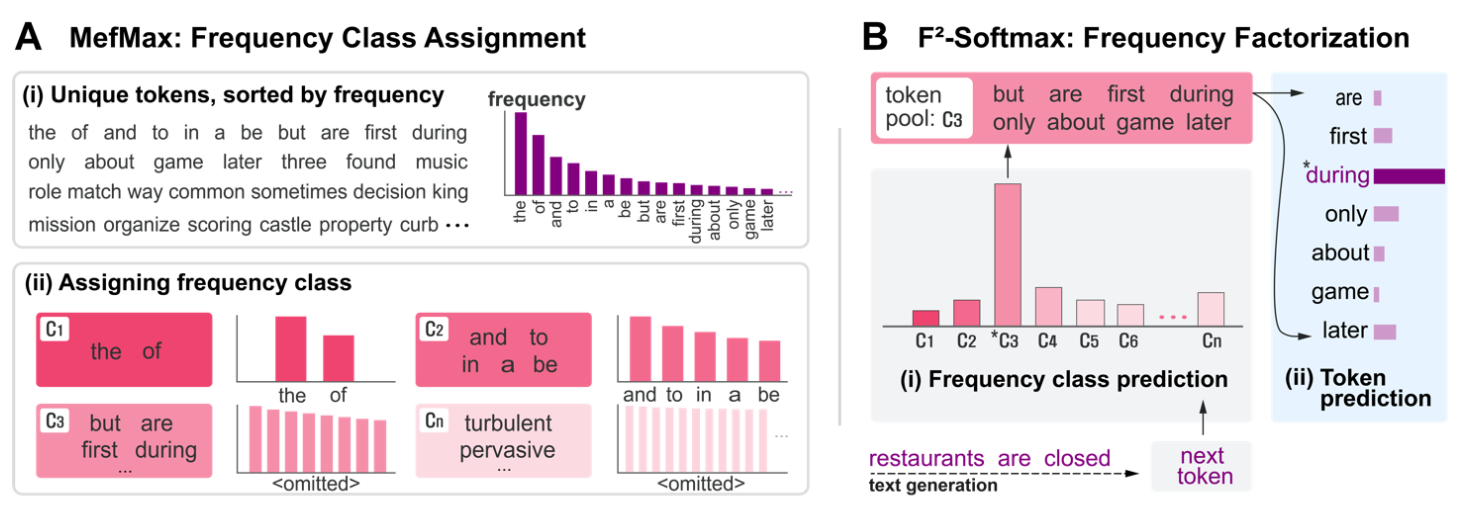
Resuilts
실험은 language modeling에 자주 사용되는 WikiText-103와 한국어 가사 데이터인 Melo-Lyrics의 두가지 데이터를 이용했고, 당연히(?) 모델은 Transformer를 이용했고, BPE tokenizer를 사용했습니다. Baseline으로는 특정 token을 덜 나오도록 하는 loss를 이용한 Unlikelihood training[1]과 frequency에 따라서 dynamic하게 cross entropy loss의 weight을 변화시키는 FACE(Frequency-Aware Cross Entropy, [7])과 비교하였습니다. Evaluation metric으로는 perplexity, KL-divergence, ML-Jaccard, Self-BLEU, Distinct-n, Repetition, Uniq의 총 7가지의 metric을 통해서 모델들을 비교했습니다. 아래는 그 결과를 보여주는데, F^2-Softmax가 대부분의 metric에서 앞서는 것을 보여줍니다. 두개의 표는 각각 stochastic과 deterministic한 decoding 방식에 따른 결과를 나타냅니다.


대부분의 경우 stochastic한 방법이 deterministic한 방법에 비해서 더 나은 결과를 보여주는데, 논문에서는 argmax를 통한 deterministic한 방법이 확률을 balance하게 만들도록 훈련시키는 이러한 접근 방법에서는 diversity를 해치기 때문이라고 얘기합니다.
또한, 실제 모델들의 frequency를 비교했을 때 아래와 같이 F^2-Softmax가 다른 모델들에 비해서 더욱 균등한 분포를 보여주는 것을 확인할 수 있습니다.

개인적으로는 간결하면서도 읽기 좋은 논문이었다고 생각합니다. 결론 부분에서 언급하듯이 문장 생성 이외에 기계번역이나 요약 등 다른 NLP task에 대해서도 좋은 성능을 보일지 궁금하기도 하고, text generation이 아니더라도 sequence를 generate하는 다른 문제들의 imbalance를 해결할 수 있는 방법이라고 보이기 때문에 NLP가 아닌 다른 domain에서도 좋은 성능을 보여줄수 있지 않을까 하는 생각이 듭니다. 다른 domain에 대해서는 아는게 적어서 뭐가 있을지는 잘 모르겠지만, 작곡같은 경우에도 불균등한 경우가 있다면 F^2-Softmax를 이용해서 좀 더 창의적인(?) 음악을 만들 수 있지 않을까..하는 뇌피셜이 있습니다.
References
[1] Welleck et. al. Neural text generation with unlikelihood training, ICLR 2020
[2] Holtzman et. al. The curious case of neural text generation, ICLR 2019
[3] Khan et. al. Striking the right balance with uncertainty, CVPR 2019
[4] Goodman et. al. Classes for fast maximum entropy training, ICASSP 2001
[5] Mnih et. al. A scalable hierarchical distributed language model, NeurIPS 2009
[6] Grave etl. al. Efficient softmax approximation for gpus, ICML 2017
[7] Jiang et. al. Improving neural response diversity with frequency-aware cross-entropy loss, WWW 2019
'Machine Learning & Deep Learning > Natural Language Processing' 카테고리의 다른 글
| Improving BERT with Syntax-aware Local Attention (0) | 2021.01.22 |
|---|---|
| Extract Training Data from Large Language Models (0) | 2021.01.11 |
| Data Augmentation in Natural Language Processing (0) | 2020.07.11 |
| Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (0) | 2020.07.05 |
| Reformer: The Efficient Transformer (1) | 2020.05.09 |



