
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Deep learning
- 자연어처리
- GPT
- Machine Learning
- Private ML
- math
- 표현론
- matrix multiplication
- AI
- Residual Connection
- Computer Vision
- 동형암호
- Knowledge Distillation
- Transformer
- NLP
- Homomorphic Encryption
- Language Modeling
- Copilot
- KT
- 머신러닝
- Natural Language Processing
- ICML
- Knowledge Tracing
- Model Compression
- attention
- Pre-training
- 딥러닝
- Data Augmentation
- Github Copilot
- bert
- Today
- Total
Anti Math Math Club
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention 본문
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
seewoo5 2020. 7. 5. 17:35이번 포스트에서는 이번 ICML2020에 accept된 Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention이라는, 제목부터 강력한 논문에 대해서 알아보겠습니다.
최근에 Transformer의 O(N^2)의 time & memory complexity를 줄이고자 하는 연구들이 굉장히 활발하게 이루어지고 있는데, 이 논문 역시 그런 연구들 중 하나로 볼 수 있습니다. (나중에 비슷한 계열의 다른 연구들도 하나씩 소개하도록 하겠습니다.) 그 중에서 유명한 것으로는 시간복잡도를 O(N\sqrt(N))으로 줄인 Sparse Transformer나 O(N log N)으로 줄인 Reformer가 있습니다. 하지만 이 역시 매우 매우 긴 sequence에 대해서 autoregressive하게 output을 뽑아내는 경우에는 부족하다고 논문에서 주장하고 있습니다. 이 논문에서는 기존의 vanilla attention(scaled dot-product attention with softmax function)을 kernel로써 해석함으로써 vanilla attention을 대체하는, 시간복잡도를 O(N)까지 줄인 linearized attention을 제안합니다. Causal language modeling이나 (pixel-wise) image generation에 사용되는 causal masking역시 linear complexity로 나타낼 수 있고, 이러한 관점에서 Transformer와 RNN사이의 관계를 밝혔다고 합니다. (개인적인 의견으로는 이 논문의 핵심은 시간복잡도를 O(N)으로 줄이는 방법을 제안했다는 점이고, RNN과의 관계를 밝힌 것은 main point가 아니라고 생각합니다.) 그렇다면 linearized attention이 무엇인지 알아보도록 합시다.
Linear Transformers
Vanilla attention의 시간복잡도를 O(N^2)으로 만드는 주범 중 하나는 softmax입니다. query와 key vector들의 (scaled) dot-product를 취하고, scaling을 한 뒤에, 각 query마다 softmax를 취해서 query별 key의 attention probability를 계산하고, 이를 weight으로써 value vector들의 weighted average를 취함으로써 attention layer의 output이 얻어집니다. 하지만, 잘 생각해보면, 굳이 softmax 함수를 써서 attention probability를 구해야 할 이유는 없습니다. 이러한 점에서 착안하여, softmax를 다른 함수로 대체한 뒤 여기서 약간의 "트릭"을 이용해서 시간복잡도를 O(N)으로 줄인 것이 바로 Linearized Attention입니다.
기존의 vanilla attention을 다시 표현하면 다음과 같이 나타낼 수 있습니다.

여기서 Q, K, V는 각각 query, key, value vector들을 나타내고, vanilla attention의 similarity function은

로 주어집니다. 그렇다면, kernel의 관점에서 similarity function을 다른 함수로 얼마든지 바꿔볼 수 있습니다. 한가지 제약 조건은 similarity function (kernel function)의 값이 양수가 되어야 한다는 것 입니다. (이는 분모가 0이 되는 것을 막아주기도 하고 직관적으로 weighted average를 취할 때 weight자체가 음수가 되는 것이 어색해서라고 생각할 수도 있습니다.) 일반적으로, feature representation map이 \phi(x)로 주어지는 경우에 (즉, k(x, y) = \phi(x)^T \phi(y)인 경우) 새로운 attention function은

로 나타낼 수 있습니다. 여기서 앞에서 잠깐 언급했던 트릭을 사용하게 되는데, 행렬의 곱이 결합법칙(associativity)를 만족한다는 사실을 이용하면, 이를 아래와 같이 고쳐서 쓸 수 있습니다.

이렇게 쓰면 뭐가 달라질까요? 달라집니다! 위의 식에서 합에 들어있는 부분은 query와 상관없는 값이기 때문에 미리 O(N)만에 계산해 놓고 각 query마다 미리 계산된 값을 이용해서 attention layer의 output을 계산하면 되기 때문에 총 시간복잡도가 O(N)으로 줄어들게 됩니다. 공간복잡도 (memory complexity) 역시 분모, 분자의 sum에 해당되는 값을 미리 저장해놓기만 하면 (각각 D by D 혹은 D by N 행렬이기 때문에 N이 D에 비해서 매우 큰 경우 O(1) 혹은 O(N)으로 볼 수 있습니다.) 이 역시 O(N)으로 줄어들게 됩니다.
Feature map의 선택지에는 여러 선택지가 있는데, 논문에서는 다음과 같은 함수를 elementwise하게 적용하는 것을 feature map으로써 사용합니다.

(elu는 exponential linear unit의 약자로, relu의 exponential version이라고 생각하면 될 것 같습니다. relu 대신에 elu를 쓰는 이유는 x < 0일 때 gradient가 0이 되는 것을 막기 위해서라고 합니다.)
Causal Masking
이전 sequence를 input으로 넣어서 다음 token을 뽑아내고, 이를 다시 input으로 넣어서 다음 token을 뽑아내는 과정을 반복하는 autoregressive한 모델을 transformer로 훈련시키기 위해서 vanilla transformer에서는 causal masking이 중요하게 사용됩니다. Linear transformer의 경우에는 따로 그런 triangular matrix 모양의 masking을 만들어 줄 필요가 없고, 위의 attention을 계산하는 식에서 합의 범위를 다음과 같이 바꿔주기만 하면 됩니다.
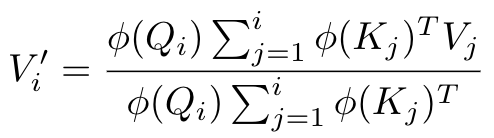
여기서 각 sum은 inductive하게 계산할 수 있으므로 이 역시 시간복잡도는 O(N)이 됩니다. 좀 더 정확히 말하면, S_i, Z_i를

로 정의했을 때, 각각은 다음의 점화식
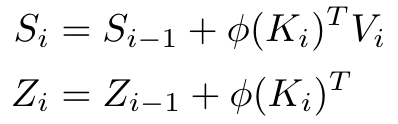
을 이용하면 O(1)만에 구할 수 있고, 따라서
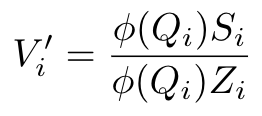
각각을 구하는 것 역시 O(1)만에 할 수 있고 총 시간복잡도는 O(N)이 됩니다.
여기서 한가지 문제가 될 수 있는 점은 gradient를 계산할 때 각 i마다 S_i에 해당하는 gradient를 모두 저장하게 되면 memory complexity가 매우 커질 수 있습니다. 이를 막기 위해서 gradient역시 위와 비슷한 방법으로 각 i에 대해서 하나씩 계산한 뒤 더해주는 방법으로 update를 하게 됩니다. 지금까지 이야기한 내용을 바탕으로 causal masking이 있는 linear transformer의 forward pass와 backward pass 알고리즘을 정리하면 다음과 같습니다.

Transformers are RNNs
Transformer는 보통 기존의 RNN 계열 모델들과 본질적으로 다르고, 개인적인 의견으로는 NLP에 있어서 RNN에서 Transformer로 넘어가면서 세대교차가 일어났다고 생각합니다. 하지만, 이 논문에서는 Transformer 역시 RNN의 일종으로 해석할 수 있다고 합니다. 위의 autoregressive한 transformer의 경우, 아래와 같이 다시 쓸 수 있습니다.

여기서 s는 attention memory, z는 normalizer memory라고 이름을 붙여주면 i-th step에 대해서 input이 x_i고 output이 y_i이면서 각 step마다 internal state s, z가 바뀌는 형태가 됩니다. 즉, RNN으로 볼 수도 있다는 것이죠. (이는 layer마다 weigth을 share해서 depth-wise하게 RNN으로 볼 수 있는 universal transformer와는 약간 다릅니다.) 여기서 더 나아가서 기존 RNN과의 깊은 비교를 하거나 RNN으로 볼 수 있다는 사실을 이용해서 뭔가를 증명하진 않았지만, 새로운 관점을 제시했다는 데에 의미가 있는 것 같습니다.
Experiments
실험은 pixel-wise image generation과 automatic speech recognition 두가지에 대해서 진행하였고, baseline은 vanilla transformer와 reformer 두가지로 두고 실험하였습니다. (처음에 보고 baseline이 부족하다는 생각이 들긴 했습니다.) 그 이전에, reformer에서 했던 synthetic한 task인 duplication task에 대해서 실험을 했을 때 reformer에 비해서 좀 더 smooth하게 수렴하고, vanilla transformer와 비슷한 loss까지 수렴하는 것을 보였습니다.
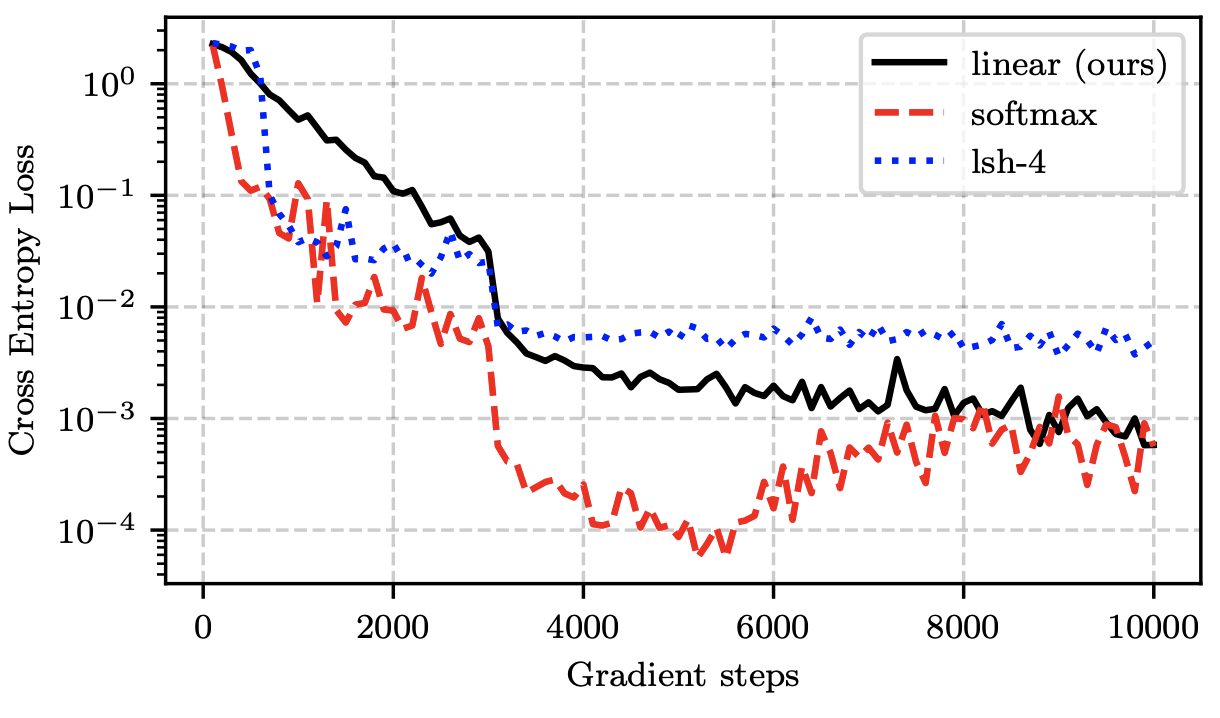
또한, synthetic하게 긴 sequence들을 만들어서 training/inference time과 memory를 비교하였는데, vanilla attention은 sequence의 길이에 대해서 quadratic하게 증가하는 데에 비해서 reformer와 linearized attention은 linear하게 증가하는 것을 볼 수 있고, linearized attention이 reformer에 비해서 memory cost가 더 작은 것을 볼 수 있습니다.

Image generation의 경우 MNIST와 CIFAR-10 dataset에 대해서 autoregressive하게 pixel을 generate하고, bpd(bits per dimension)으로 성능을 비교하였습니다. MNIST의 경우 vanilla transformer에 비해서 성능은 좋지 않았지만, locality sensitive hashing을 사용한 reformer에 비해서는 성능이 좋게 나왔고, 속도는 무려 vanilla에 비해서 317배나(!) 빨라진 것을 볼 수 있습니다. (여기서 reformer가 vanilla에 비해서 그리 빠르지 않은 것을 볼 수 있는데, MNIST의 pixel 수가 28 * 28 = 784개로 그리 많지 않기 때문입니다.) CIFAR-10의 경우에는 vaniila에 비해서 성능도 좋아졌고, 속도는 4000배정도 빨라졌다고 합니다.

Automatic speech recognition에서는 80h WSJ dataset에 대해서 실험한 뒤 PER(phoneme error rate)로 성능을 비교하였는데요, reformer에 비해서는 성능, 속도 면에서 모두 좋아졌고, vanilla transformer에 비해서 성능은 안좋아졌지만 속도는 3배정도 빨라졌습니다.

개인적으로는 다른 dataset에 대해서 더 실험을 했으면 좋겠다는 생각이 들었지만, linearized attention을 이용해서 O(N)으로 줄인 아이디어는 맘에 들었습니다. 이런 방향의 연구가 엄청나게 많이 이루어지고 있는데, 성능, 효율의 두마리 토끼를 잡을 수 있는 모델이 더 많이 나왔으면 좋겠습니다.
'Machine Learning & Deep Learning > Natural Language Processing' 카테고리의 다른 글
| Extract Training Data from Large Language Models (0) | 2021.01.11 |
|---|---|
| F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax (0) | 2020.12.14 |
| Data Augmentation in Natural Language Processing (0) | 2020.07.11 |
| Reformer: The Efficient Transformer (1) | 2020.05.09 |
| Synthesizer: Rethinking Self-Attention in Transformer Models (4) | 2020.05.09 |



