
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Transformer
- KT
- AI
- Model Compression
- Knowledge Distillation
- bert
- Computer Vision
- Knowledge Tracing
- Data Augmentation
- Private ML
- Copilot
- Residual Connection
- 표현론
- 동형암호
- Machine Learning
- attention
- Deep learning
- GPT
- 딥러닝
- Natural Language Processing
- 자연어처리
- ICML
- Pre-training
- Github Copilot
- 머신러닝
- Homomorphic Encryption
- math
- NLP
- Language Modeling
- matrix multiplication
- Today
- Total
Anti Math Math Club
Synthesizer: Rethinking Self-Attention in Transformer Models 본문
Synthesizer: Rethinking Self-Attention in Transformer Models
seewoo5 2020. 5. 9. 16:38이번 포스트에서는 Google에서 며칠전에 발표한 따끈따끈한 논문인 Synthesizer: Rethinking Self-Attention in Transformer Models에 대해서 리뷰하고자 합니다.
2017년에 Google에서 발표한 Transformer는 NLP에서 새로운 혁명을 가져왔다고 해도 과언이 아닙니다. 기존에 있던 RNN계열의 모델들이 parellel하게 train할 수 없다는 단점을 Attention만을 이용해서 해결하고, Machine Translation을 포함한 여러 NLP task에서 성능 역시 큰 폭으로 향상시켜서 지금까지도 Language Modeling, Language Generation, Music Generation, Image Generation등의 여러 seq2seq 문제들에 사용되고 있습니다. 다양한 NLP task들의 기반이 되는 pre-training 방법론인 BERT와 그의 여러 variation들(ALBERT, SciBERT, BioBERT, ERNIE 등)에 쓰이기도 하구요.
Transformer에서의 Attention은 주어진 input을 Query, Key, Value로 embedding한 뒤, 이를 이용해서 다음과 같이 계산합니다.

이를 해석해보면 주어진 query vector에 대해서 각 key vector가 얼마나 attend 하는지 (얼마나 중요한지) scaled dot-product로 계산한 뒤, softmax를 통해서 각 key의 가중치를 얻고, 최종 output은 이 가중치에 대한 value vector들의 weighted sum이 됩니다. 최근에는 Reformer, Sparse Transformer를 비롯해서 Attention 계산의 time complexity인 O(L^2)을 줄이려는 연구도 활발하게 진행되고 있습니다. (여기서 L은 sequence의 길이를 의미합니다.)
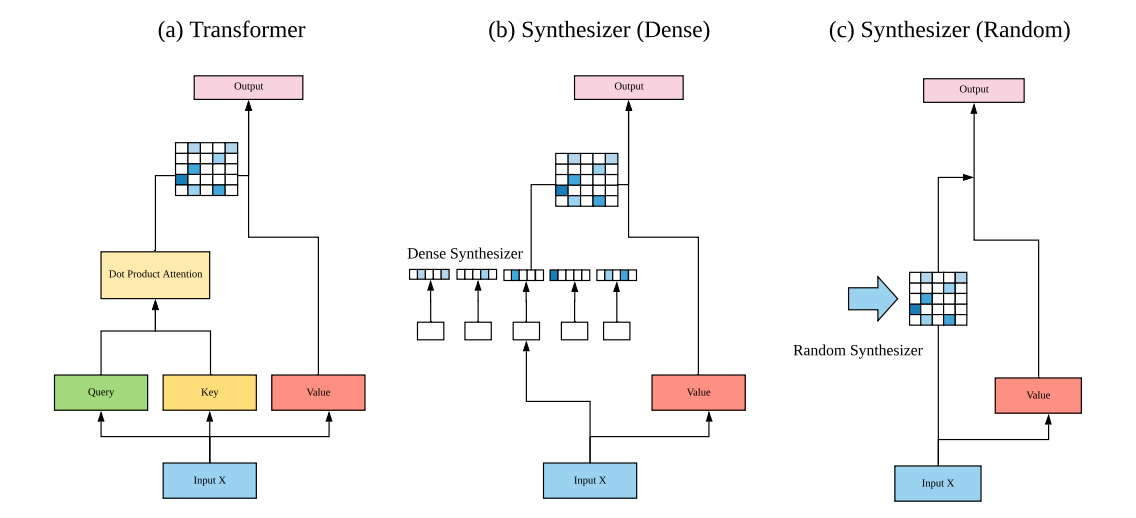
여기서 Synthesizer의 저자들은 다음과 같은 생각을 합니다. 정말로 dot-product attention이 중요한 것일까? Dot-product attention이 무엇을 하는지 다시 한번 생각해보면, 각 query와 key 사이의 interaction, 즉 token과 token 사이의 interaction에 집중하고 있습니다. 이 외에도 중요하게 사용될 수 있는 정보들을 생각해보면, individual token information과 input과 관계없는, task에만 의존하는 global task information이 있을 수 있습니다. Synthesizer의 핵심은 기존의 dot-product attention을 대체하면서 이러한 정보들을 잘 모델링 할 수 있다는 것에 있습니다. 논문에서 제시된 Synthesizer에는 크게 Dense Synthesizer(individual token information)와 Random Synthesizer(global task information)의 두가지가 있습니다.
1. Dense Synthesizer
Dense Synthesizer는 기존의 token-token interaction을 모델링하는 dot-product attention을 individual token information을 모델링하는 2-layer feed-forward network으로 바꾼 것을 말합니다. 좀 더 구체적으로, 다음과 같이 정의됩니다. 2-layer feed-forward network (with ReLU activation function)

에 대해서,

로 정의합니다. 여기서 G(X)는 기존과 동일하게 value embedding matrix를 곱하는 함수라고 보면 됩니다. (G(X) = XW^V) Attention weight이 token의 pairwise information이 아닌 각 token에만 의존하게 되는 것이죠.
2. Random Synthesizer
Random Synthesizer는 Dense Synthesizer에 비해서 더 간단합니다. 위와 비슷하게 다음과 같은 식으로 정의됩니다.

여기서 G(X)는 앞과 동일하고, L by L matrix인 R은, 이름에서 알 수 있듯이, random하게 초기화된 matrix입니다. 이는 input에도 의존하지 않고, trainable하거나 고정할 수도 있습니다. 이는 global task information만을 capture한다고 볼 수 있습니다.
3. Factorized Models
위에서 언급한 두 Synthesizer는 모두 O(L^2)의 time & space complexity를 가집니다. 길이가 긴 sequence를 다루게 되면 이게 bottleneck이 될 수도 있는데요, 이를 해결하기 위해서 다음과 같은 Dense, Random Synthesizer의 factorized variation을 제안합니다.
Dense Synthesizer의 경우는, 먼저 하나가 아닌 두개의 feed-forward layer F_A, F_B를 생각합니다. 여기서 ab=L을 만족하는 고정된 a, b에 대해서

이고, 기존의 Dense Synthesizer에서 Softmax안에 들어가던 행렬을

로 대체합니다. 여기서 H_A, H_B는 각각 input을 b, a번 복제하는 tiling function이고, 따라서 H_A(A)와 H_B(B)는 각각 L by L 행렬이 됩니다. 이렇게 만들어진 두 행렬을 곱해서 C를 만들고, 이를 가지고

를 통해서 output을 얻게 됩니다. 이는 기존의 space complexity를 O(dL + L^2)에서 O(dL + L(a+b))로 줄여주고, a = b = \sqrt{L}로 잡으면 O(dL + 2L^1.5)로 minimize가 됩니다. (논문에서는 실제 실험에서 a, b를 무엇으로 잡았는지는 언급하지 않고 있습니다.)
마찬가지로 Random Synthesizer역시 random matrix R을 low-rank matrix R_1, R_2의 곱 R = R_1 * R_2^T로 둬서 time & space complexity를 O(L^2)에서 O(2Lk)로 줄일 수 있습니다. 저자들은 이러한 factorized-variation들이 complexity를 줄일 뿐만 아니라 overfitting을 방지하는 역할도 할 수 있다고 합니다. (논문에서는 k를 8로 잡았다고 합니다.)
4. Vanilla Attention as Synthesizer
Vanilla Transformer에 사용된 dot-product attention역시 Synthesizer의 한 종류로 생각할 수 있습니다.

라고 두면 Y = Softmax(S(X))G(X)로 나타낼 수 있기 때문이죠. 앞에서 언급했듯이, dot-product attention은 token-token interaction을 modeling한다고 볼 수 있습니다.
5. Mixture of Synthesizers
위에서 언급한 여러개의 Synthesizer를 같이 사용할 수도 있습니다. N개의 Synthesizer S_1, ..., S_N이 주어졌을 때, 합이 1이고 양수인 learnable weight들 alpha_1, \dots, \alpha_N에 대해서

라고 둘 수 있습니다. 예를 들어, Factorized Random Synthesizer와 Standard Dense Synthesizer를 결합하면
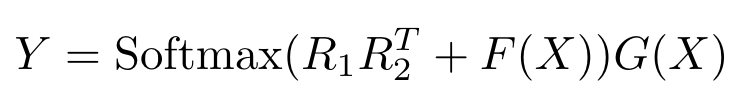
로 나타낼 수 있는 것이죠.
앞에서 언급한 Synthesizer들을 표로 나타내면 다음과 같습니다.

위의 Synthesizer들을 하나씩 보다 보면 누구나 같은 생각을 하게 됩니다. 이게 된다고? 심지어 저자들 역시 factorized variation에 대해서는 자신들도 처음에 성능이 좋을 것이라고 기대를 안했다고 각주에 써 놨습니다. 이게 무슨 의미일까요? 실제로 실험을 해 보면, 잘 됩니다!
논문에서는 Machine Translation, Language Modeling, Text Generation (Summarization & Dialogue Generation), Multi-Task Natural Language Processing 등 굉장히 많은 task에 대해서 실험을 진행하였고, 결과는 놀랍게도 우리의 생각과는 다르게 Dense & Random Synthesizer가 생각보다 성능이 좋게 나옵니다.

먼저, Machine Translation의 결과를 보면, 기존의 Vanilla Transformer에 비해서 Random이나 Dense Synthesizer를 쓴 모델의 BLEU score가 크게 낮지 않음을 볼 수 있습니다. (심지어, 원 논문에 report된 결과에 비해서는 performance가 좋아집니다.) 심지어, Factorized Random이나 Dense의 경우 parameter수가 줄었는데도 불구하고 성능에서의 차이가 별로 없습니다. 가장 좋은 모델은 28.47의 BLEU score를 달성한 Random과 Vanilla를 같이 쓴 모델이라고 합니다. Language Modeling의 경우, Dense + Vanilla가 다른 Baseline들에 비해서 가장 좋은 성능을 보입니다. Fixed Random의 성능이 크게 좋지 않은 것은 어쩌면 당연하지만, Trainable한 Random Synthesizer의 성능이 기존 Vanilla Transformer에 비해서 크게 뒤지지 않는다는 것은 꽤 놀랍습니다.

Summarization과 Dialogue Generation을 포함하는 Text Generation의 결과는 더 놀랍습니다. Dialogue generation의 경우, Dense Synthesizer만 사용한 모델이 Vanilla Transformer에 비해서 모든 task에 비해서 consistent하게 좋은 성능을 보이고 있습니다. 저자들은 이 task들에 대해서는 token-token interaction에 집중하는 것이 모델의 성능이 오히려 해가 될 수 있다고 해석하고 있습니다.

마지막으로, T5(Text-to-Text Transformer)를 baseline으로 삼아서 GLUE/SuperGLUE benchmark에 실험을 한 결과도 나와있습니다. 표에서 볼 수 있듯이, Random 혹은 Dense Sythesizer만 사용한 모델은 성능이 좋지 않지만, Random과 Vanilla를 같이 사용한 모델은 기존 baseline에 비해서 성능이 크게 향상되는 것을 볼 수 있습니다.
이 외에도, 각 Synthesizer로 train된 attention weight(softmax를 취한 결과값)의 분포와 head 갯수 별 성능에 대해서 실험한 결과도 나타나 있습니다. 아래의 그래프를 보면 각 layer에 대해서는 비슷한 분포를 보이고, layer 내에서는 Vanilla Synthesizer에 비해서 Random이나 Dense가 더 variation이 높게 나타나고, Dense Synthesizer의 weight은 0 근처에 몰려있는 반면, Random Synthesizer는 좀 더 0에서 멀리 퍼져있습니다. head 갯수에 따른 성능은 pre-training을 하지 않은 T5를 Machine Translation에 적용했을 때, head 수가 증가할 수록 성능 역시 올라가는 것을 확인했습니다.


결론적으로, 이 논문에서는 기존 Transformer의 dot-product attention이 꼭 필요한지에 대한 질문의 답이 NO라는 것을 많은 실험을 통해서 확인하였고, tokenwise information이나 global task information을 모델링하는 Dense/Random Synthesizer로 충분히 대체될 수 있음을 보였습니다. (Dialogue generation에서는 오히려 dot-product attention이 독이 된다는 것도 보였구요.) Transformer가 3년전에 나왔음에도 불구하고 아직까지도 활발한 연구가 이루어지고 있는데, 이러다가는 You don't need attention at all같은 논문이 나오는게 아닌가 싶습니다.
Appendix. Random이나 Dense Synthesizer이외에도 1D-Convolution, Bottleneck (feed-forward layer의 중간 dimension을 16으로 매우 작게 잡음), Gated Linear Unit등을 이용한 Synthesizer에 대해서도 실험을 해보았다고 나와있지만, 성능이 Random이나 Dense에 비해서 그리 좋지 않아서 자세히는 언급하지 않는다고 되어있습니다.
'Machine Learning & Deep Learning > Natural Language Processing' 카테고리의 다른 글
| Extract Training Data from Large Language Models (0) | 2021.01.11 |
|---|---|
| F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax (0) | 2020.12.14 |
| Data Augmentation in Natural Language Processing (0) | 2020.07.11 |
| Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (0) | 2020.07.05 |
| Reformer: The Efficient Transformer (1) | 2020.05.09 |



