
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- attention
- 자연어처리
- Computer Vision
- ICML
- Data Augmentation
- Model Compression
- 머신러닝
- Residual Connection
- Github Copilot
- 딥러닝
- 표현론
- matrix multiplication
- AI
- Deep learning
- Transformer
- bert
- Pre-training
- Homomorphic Encryption
- Private ML
- KT
- Machine Learning
- Natural Language Processing
- Knowledge Distillation
- Copilot
- GPT
- Knowledge Tracing
- 동형암호
- Language Modeling
- math
- NLP
- Today
- Total
목록전체 글 (26)
Anti Math Math Club
 Constructions in combinatorics via neural networks
Constructions in combinatorics via neural networks
이번에는 기존에 이 블로그에서 리뷰하던 대부분의 딥러닝 논문들과는 성격이 좀 다르지만 굉장히 흥미로운 결과를 담고 있는 논문을 리뷰하고자 합니다. 저는 지금은 인공지능 관련 일을 하고 있지만 본업은 수학이며 학위를 진행중인 상태입니다. 그래서인지 인공지능 공부를 하면서 가장 궁금했던것은 인공지능이 정말로 논리적인 '사고'라는것을 할 수 있는지, 특히 수학적인 명제에 대한 '증명'을 스스로 할 수 있는지에 대해서 의문을 자주 가졌습니다. 예전에는 정말 머나먼 이야기라고 생각했지만, 요즘에는 생각이 조금씩 바뀌고 있습니다. 최근에 Lean이라는 언어를 이용해 수학의 매우 기본적인 공리들부터 시작해서 최신 이론들까지 컴퓨터로 formalize하려는 시도가 여러 사람들에 의해서 이루어지고 있고, 이 프로젝트의 ..
 Attention is not all you need: pure attention losses rank doubly exponentially with depth
Attention is not all you need: pure attention losses rank doubly exponentially with depth
이번에는 제목을 보자마자 어그로가 끌려서 읽을 수 밖에 없었던 Attention is not all you need: pure attention losses rank doubly exponentially with depth라는 논문에 대해서 리뷰하겠습니다. Attention is all you need라는 제목으로 NeurIPS에 발표된 논문은 자연어 처리 뿐만 아니라 요즘에는 컴퓨터 비전까지 넘보고 있는 Transformer를 제시한 역사적인 논문입니다. Transformer는 self-attention만을 이용하여 기존의 RNN 기반 모델들에 비해서 자연어 처리에서의 월등한 성능과 훈련 속도를 보여주었고, 이후 GPT와 BERT를 필두로 한 자연어 처리에서의 pre-training & fine-tun..
 Pretrained Transformers as Universal Computation Engines
Pretrained Transformers as Universal Computation Engines
이번 포스팅에서는 꽤 최근에 UC Berkeley, FAIR, Google Brain에서 공동으로 발표한 Pretrained Transformers as Universal Computation Engines라는 논문에 대해서 리뷰하도록 하겠습니다. 논문의 내용을 한줄로 요약하자면 다음과 같습니다. Language pre-trained Transformer (e.g. GPT)를 잘 fine-tuning하면 NLP가 아닌 다른 task (image classification 등)에서도 좋은 성능을 보여줄 수 있다! 누군가 한번쯤 해봤을 생각이지만, 단순히 생각했을 때는 잘 될 것 같지 않기 때문에 실제로 해본 사람이 없었던, 그런 느낌입니다. 이 논문은 실제로 가능하다는 것을 보여준 논문이라고 할 수 있고요..
 Patient Knowledge Distillation for BERT model compression
Patient Knowledge Distillation for BERT model compression
이번 포스팅에서는 EMNLP 2019에 accept된 Patient Knowledge Distillation for BERT model compression이라는 논문을 리뷰하도록 하겠습니다. Knowledge Distillation(KD)이란 커다란 모델(teacher model)의 학습된 '지식'을 작은 모델(student model)로 '증류'하는 방법으로 모델의 크기를 줄이는 것을 말합니다. Hinton의 Distilling the Knowledge in a Neural Network라는 논문에서 처음 제안되었는데, 다음과 같은 순서로 진행합니다. 먼저 teacher model을 학습시킵니다. student model을 학습시킬 때, loss를 실제 학습에 사용되는 loss(예를들어, BCE lo..
 ReZero is All You Need: Fast Convergence at Large Depth
ReZero is All You Need: Fast Convergence at Large Depth
딥러닝의 발전에 있어서 중요한 발견 중 한가지는 ResNet의 발명이라고 할 수 있습니다. 매우 deep한 뉴럴넷을 학습시키기위해서 input의 정보를 그대로 output에 더해줌으로써 모델은 input과 output의 "차이"에 해당하는 부분만 학습할 수 있도록 해주는 것 입니다. 실제로 Residual Connection을 사용했을 대 vanishing gradient problem도 어느정도 해결이 된다고 알려져 있습니다. 하지만 시간이 지날수록 점점 더 크고 깊은 모델을 사용하게 되면서, Residual Connection만으로는 부족하다고 느껴지고 이를 개선한 여러가지 모델들과 방법론이 등장하게 됩니다. 예를 들어서, Batch Normalization이나 Layer Normalization과 ..
22.03.17) 제가 훈련소를 다녀온지 거의 1년이 지났는데, 아직도 생각보다 많은 분들이 이 글을 읽고 있는 것 같습니다. 샤워실을 처음 3일동안 못쓴다던지 하는건 제가 다녀온 뒤로 바뀌었다고 들었고 그 이외에도 코로나 관련 훈련소 정책들이 많이 달라진 것으로 들었는데, 수정하거나 업데이트할만한 내용이 있으시다면 덧글로 남겨주세요. 반영하겠습니다. 저는 모 스타트업에서 전문연구요원으로 일하고 있습니다. 계속 논문쓰고 일하느라 바빠서 훈련소를 미루다가 더이상 미룰 수 없기에 2/18~3/11에 다녀오게 되었는데 3주로 줄어든 전문연구요원 훈련소와 코로나 시대에서 어떻게 달라졌는지에 대해서 간략하게 요약하고자 합니다. 이 포스팅은 제 개인 일기를 바탕으로 하고 있습니다. 준비물 저는 대부분의 준비물을 여..
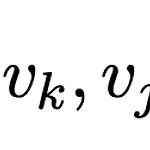 Improving BERT with Syntax-aware Local Attention
Improving BERT with Syntax-aware Local Attention
이번에는 짧고 간단한 논문인 Improving BERT with Syntax-aware Local Attention이라는 논문을 리뷰하도록 하겠습니다. 최근 NLP의 동향은 커다란 트랜스포머 모델을 pre-training시킨 뒤 원하는 downstream task에 fine-tuning하는 것 입니다. GPT와 BERT를 시작으로 다양한 pre-training 기법과 다양한 크기의 트랜스포머들이 세상에 나왔습니다. 그 중에서는 attention mechanism을 개선해서 좀 더 성능을 높이거나 혹은 연산량을 줄이는 방향의 연구가 많습니다(Reformer, Longformer, Sparse Transformer, Synthesizer 등). 이 논문에서는 syntax 정보를 이용해서 attention m..
 Extract Training Data from Large Language Models
Extract Training Data from Large Language Models
이번 포스팅에서는 작년 12월에 arXiv에 등장하여 꽤나 화제가 되었던 논문인 Extract Training Data from Large Language Models라는 논문을 리뷰하도록 하겠습니다. 제목에서 알 수 있듯이 이 논문의 요지는 훈련된 language model로부터 training data를 역으로 추출하는 방법에 대한 이야기를 다루고 있습니다. 여기서 다루는 주제의 중요성은 논문 첫 페이지에 있는 Figure 1로부터 바로 알 수 있습니다. 위의 그림에서 볼 수 있듯이 GPT-2에 특정 prefix를 집어넣은 뒤 뒤에 올 token들을 생성하게 되면 training set의 일부인 누군가의 개인정보가 그대로 나올 수 있다는 것입니다. (GPT-2의 traning set은 논문에서 볼 수..