
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Pre-training
- NLP
- 자연어처리
- Computer Vision
- Copilot
- math
- Language Modeling
- 동형암호
- Knowledge Tracing
- bert
- Data Augmentation
- KT
- Transformer
- Knowledge Distillation
- Deep learning
- Natural Language Processing
- Github Copilot
- 머신러닝
- Homomorphic Encryption
- 딥러닝
- Machine Learning
- AI
- attention
- GPT
- Model Compression
- ICML
- Private ML
- matrix multiplication
- 표현론
- Residual Connection
- Today
- Total
목록Deep learning (19)
Anti Math Math Club
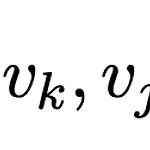 Improving BERT with Syntax-aware Local Attention
Improving BERT with Syntax-aware Local Attention
이번에는 짧고 간단한 논문인 Improving BERT with Syntax-aware Local Attention이라는 논문을 리뷰하도록 하겠습니다. 최근 NLP의 동향은 커다란 트랜스포머 모델을 pre-training시킨 뒤 원하는 downstream task에 fine-tuning하는 것 입니다. GPT와 BERT를 시작으로 다양한 pre-training 기법과 다양한 크기의 트랜스포머들이 세상에 나왔습니다. 그 중에서는 attention mechanism을 개선해서 좀 더 성능을 높이거나 혹은 연산량을 줄이는 방향의 연구가 많습니다(Reformer, Longformer, Sparse Transformer, Synthesizer 등). 이 논문에서는 syntax 정보를 이용해서 attention m..
 Extract Training Data from Large Language Models
Extract Training Data from Large Language Models
이번 포스팅에서는 작년 12월에 arXiv에 등장하여 꽤나 화제가 되었던 논문인 Extract Training Data from Large Language Models라는 논문을 리뷰하도록 하겠습니다. 제목에서 알 수 있듯이 이 논문의 요지는 훈련된 language model로부터 training data를 역으로 추출하는 방법에 대한 이야기를 다루고 있습니다. 여기서 다루는 주제의 중요성은 논문 첫 페이지에 있는 Figure 1로부터 바로 알 수 있습니다. 위의 그림에서 볼 수 있듯이 GPT-2에 특정 prefix를 집어넣은 뒤 뒤에 올 token들을 생성하게 되면 training set의 일부인 누군가의 개인정보가 그대로 나올 수 있다는 것입니다. (GPT-2의 traning set은 논문에서 볼 수..
 F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax
F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax
이번 포스팅에서는 올해 EMNLP에 나온 F^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax에 대해서 리뷰하겠습니다. Introduction Text generation이란 말 그대로 문장을 생성하는 task를 말합니다. 대화 시스템, 기계번역, 요약 등 여러가지에 사용되는 NLP의 기본적인 task중 하나라고 생각할 수 있습니다. 기존의 text generation의 대부분은 language modeling, 즉 문장의 분포를 autoregressive하게 모델링하는 방법으로 모델을 훈련시키고, 이때 loss는 negative log likelihood를 사용합니다. 즉, likelihood를 최대화하는 방향..
 Neural Ordinary Differential Equation
Neural Ordinary Differential Equation
이번 포스팅에서는 2018년도 NeurIPS에서 best paper award를 받은 Neural Ordinary Differential Equation(이하 NODE, Neural ODE, ODE-Net, ODE Network)이라는 논문에 대해서 리뷰하도록 하겠습니다. Ordinary Differential Equation(상미분방정식, ODE)란 미분 방정식 중에서 구하려는 함수가 하나의 변수에만 의존하는 경우를 말합니다. 일반적으로 다음과 같은 형태를 가집니다. 예를 들어서, 간단하면서 구체적으로 해를 구할 수 있는 경우로는 f가 z에 대한 행렬곱으로 주어지는 경우, 즉 인 경우이고 이때 해는 로 주어집니다. (행렬의 지수에 관해서는 위키피디아를 참고하시길 바랍니다.) ODE는 왜 갑자기 나오는걸..
 Generative Pretraining from Pixels
Generative Pretraining from Pixels
이번 포스팅에서는 ICLR 2020 Honorable Mention Award를 받은 Generative Pretraining from Pixels라는 논문에 대해서 알아보도록 하겠습니다. Computer Vision에서는 ImageNet을 이용한 pre-training & fine-tuning이 거의 표준으로 자리잡고 있는 반면, NLP에서는 Wikipedia같은 거대한 corpus가 있다고 해도 sentiment나 POS tag같은 label이 붙어 있는 데이터는 많지 않기 때문에 pre-training을 하는 것이 쉽지 않습니다. 하지만, GPT와 BERT를 기점으로 한 self-supervised learning은 이러한 데이터를 활용해서 모델을 똑똑하게 pre-train하는 것을 가능하게 해 주..
 Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning
이번 포스트에서는 (제가 알기로는) Consistency Regularization이 처음 소개된 논문인 Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning이라는 논문에 대해서 알아봅시다. Consistency Regularization이란, 간단히 말해서 모델의 Input에 augmentation을 가해서 새로운 input을 만들었을 때, output (prediction)이 별로 변하지 않아야 한다는 가정을 바탕으로 모델을 regularize하는 방법 입니다. 예를 들어서, 이미지를 분류하는 CNN이 하나 있을 때, 기존에 있던 강아지 사진을 뒤집거나 돌리는 등의 작업을 해서 ..
 qDKT: Question-centric Deep Knowledge Tracing
qDKT: Question-centric Deep Knowledge Tracing
이번 포스트에서는 qDKT: Question-centric Deep Knowledge Tracing에 대해서 알아보도록 하겠습니다. DKT, DKVMN등을 비롯한 대부분의 Knowledge Tracing 모델들은 학생의 knowledge를 skill-level로써 모델링합니다. 즉, 학생의 과거의 interaction = (skill_id, correctness)를 바탕으로 다음 문제의 skill에 해당하는 정오답을 예측합니다. 하지만, 같은 skill을 가지는 문제일지라도 문제 자체는 다르기 같은 skill의 서로 다른 문제들을 하나로 엮는 것은 정보를 잃는다고 생각할 수 있습니다. 또한, 문제의 skill이라는 것이 모든 데이터셋에 대해서 항상 존재한다고 볼 수도 없습니다. (일반적으로 skill은 ..
 Data Augmentation in Natural Language Processing
Data Augmentation in Natural Language Processing
보통 머신러닝 혹은 딥러닝 연구에서 어떤 문제를 풀 때 데이터가 부족한 경우 해결책으로써 가장 많이 생각하는 방법은 data augmentation 혹은 transfer learning (pre-training & fine-tuning) 입니다. 전자는 기존에 존재하는 데이터를 특정 방식으로 변형하여 비슷한 가상의 데이터를 만들어내는 것이고, 후자는 같은 도메인이지만 훨씬 더 크기가 큰 데이터에 대해서 모델을 먼저 훈련시킨 뒤 (pre-training), 원래의 데이터에 맞게 파라미터를 미세하게 조정해주는 (fine-tuning) 방법입니다. CV(Computer Vision)에서는 data augmentation 기법으로는 주어진 이미지를 자르고 붙이고 늘이고 뒤집는 등의 방법이 있고, transfer..