
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Copilot
- Residual Connection
- 표현론
- AI
- Machine Learning
- math
- Github Copilot
- Knowledge Tracing
- Natural Language Processing
- NLP
- 딥러닝
- Model Compression
- ICML
- Language Modeling
- 머신러닝
- Pre-training
- 동형암호
- Deep learning
- Computer Vision
- GPT
- Knowledge Distillation
- bert
- Data Augmentation
- KT
- Homomorphic Encryption
- Transformer
- Private ML
- matrix multiplication
- 자연어처리
- attention
- Today
- Total
목록NLP (11)
Anti Math Math Club
 Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
이번 포스트에서는 이번 ICML2020에 accept된 Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention이라는, 제목부터 강력한 논문에 대해서 알아보겠습니다. 최근에 Transformer의 O(N^2)의 time & memory complexity를 줄이고자 하는 연구들이 굉장히 활발하게 이루어지고 있는데, 이 논문 역시 그런 연구들 중 하나로 볼 수 있습니다. (나중에 비슷한 계열의 다른 연구들도 하나씩 소개하도록 하겠습니다.) 그 중에서 유명한 것으로는 시간복잡도를 O(N\sqrt(N))으로 줄인 Sparse Transformer나 O(N log N)으로 줄인 Reformer가 있습니다. 하지만 이 역시 매우 매..
 Reformer: The Efficient Transformer
Reformer: The Efficient Transformer
이번 포스트에서는 Google에서 올해 초에 발표하고 ICLR2020에 accept된 Reformer: The Efficient Transformer에 대해서 알아보도록 하겠습니다. Synthesizer 리뷰에서도 언급했었지만, 2017년에 Google에서 발표한 Transformer는 NLP를 포함해서 music generation, image generation, knowledge tracing, time series prediction등 여러가지 seq2seq task에서 state-of-the-art의 성능을 보여주고 있습니다. CNN 모델들이 그렇듯이, NLP 혹은 다양한 seq2seq 문제를 해결하기 위해서 점점 더 큰 Transformer를 사용하게 되고, 최근에 Microsoft에서 발표한..
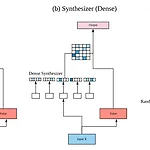 Synthesizer: Rethinking Self-Attention in Transformer Models
Synthesizer: Rethinking Self-Attention in Transformer Models
이번 포스트에서는 Google에서 며칠전에 발표한 따끈따끈한 논문인 Synthesizer: Rethinking Self-Attention in Transformer Models에 대해서 리뷰하고자 합니다. 2017년에 Google에서 발표한 Transformer는 NLP에서 새로운 혁명을 가져왔다고 해도 과언이 아닙니다. 기존에 있던 RNN계열의 모델들이 parellel하게 train할 수 없다는 단점을 Attention만을 이용해서 해결하고, Machine Translation을 포함한 여러 NLP task에서 성능 역시 큰 폭으로 향상시켜서 지금까지도 Language Modeling, Language Generation, Music Generation, Image Generation등의 여러 seq2..